

Performance Evaluation of PowerInfer‑2: Offloading, Prefill, and In‑Memory Efficiency
Table of Links
Abstract and 1. Introduction
- Background and Motivation
- PowerInfer-2 Overview
- Neuron-Aware Runtime Inference
- Execution Plan Generation
- Implementation
- Evaluation
- Related Work
- Conclusion and References
7 Evaluation
In this section, we evaluate the performance of PowerInfer-2 for various models and smartphone hardwares.
\
7.1 Experimental Setup
Hardware. We select one high-end and one mid-end OnePlus [25] smartphone for evaluation, with details listed in Table 3. We choose these smartphones for two reasons. First, the hardware configurations are representatives of high-end and mid-end smartphones. OnePlus 12 is a high-end smartphone model equipped with flagship hardware including a top-tier Qualcomm SoC, while OnePlus Ace 2 represents the previous generation of smartphones. Second, both phones allow rooting so we can bypass vendor-specified application constraints to unlock the full computing capabilities of smartphones.
\ Models. We choose four language models of varying architectures and model sizes, namely TurboSparse-Mistral-7B[3] [31] (“Mistral-7B” in figures for short), sparse Llama-7B/13B [29], and TurboSparse-Mixtral-47B[4] [31] (“Mixtral-47B” in figures for short).
\ Baselines. We compare PowerInfer-2 with three state-of-theart LLM inference frameworks: llama.cpp [13], LLM in a Flash [4], and MLC-LLM [33]. Llama.cpp is currently the fastest large model inference framework that supports offloading part of model weights to flash storages (via mmap), and also serves as the backend for many other frameworks, such as Ollama [2]. LLM in a Flash (called LLMFlash in the evaluation) is designed for the PC context and not open-sourced. Therefore we have ported it to llama.cpp by implementing sparsity prediction, row-column bundling, neuron data caching and memory management in llama.cpp according to the descriptions in the original paper. MLC-LLM utilizes mobile GPUs to accelerate large model inference but it does not support weight offloading. It cannot run when the size of model parameters exceeds the available memory size. Therefore, we only compare PowerInfer-2 with MLC-LLM in scenarios where inferences can be performed entirely in memory.
\ For PowerInfer-2 and LLMFlash, we deployed our sparsified models, while for other baseline systems, we employed the original models for speed comparison.
\ Workloads. The workloads for evaluation are selected from
\ 
\ practical LLM tasks, including multi-turn dialogue [35], code generation [9], math problem solving [10], and role play [36], in order to fully demonstrate the efficiency of PowerInfer-2. Notably, these selected workloads are the top representatives of real-world tasks from the huggingface community. We use prompt lengths of 128 and 512 tokens to test prefill performance. For decoding test, we use prompts of at most 64 tokens and generate up to 1,024 tokens. All test runs are repeated 10 times to average out fluctuations.
\ Key Metrics. As we focus on low latency setting, our primary evaluation metric centers on the end-to-end generation speed. In our evaluation, we adopted prefill speed (tokens/s) and decoding speed (tokens/s) as our metrics to provide a more straightforward representation of the system’s performance.
\
7.2 Offloading-Based Performance
In this section, we evaluate the performance of decoding and prefill of PowerInfer-2 on different models when the amount of available memory is restricted, and compare PowerInfer-2 with llama.cpp and LLMFlash.
\ 7.2.1 Decoding Performance
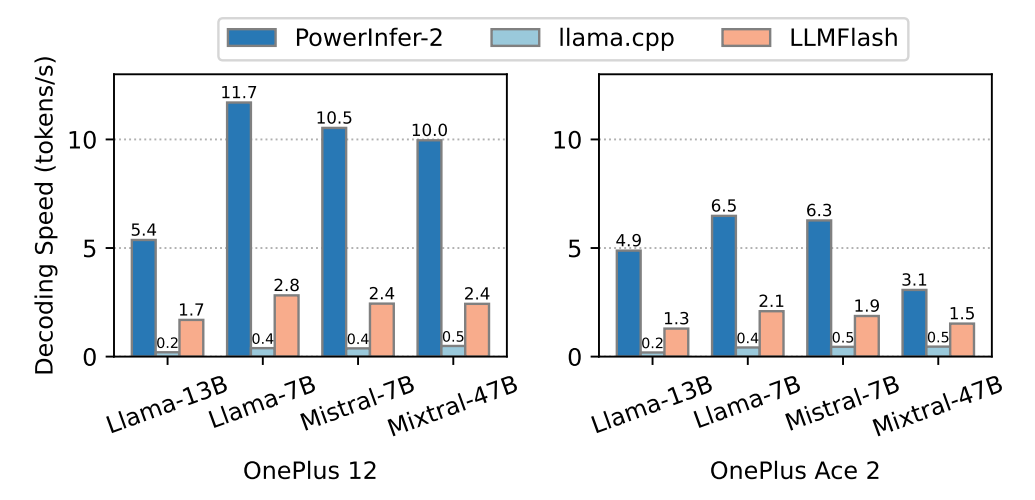
We first compare the decoding speed of PowerInfer-2 with the state-of-the-art LLM inference frameworks. We limit the placement of weights of FFN blocks in DRAM to 50% for all models except TurboSparse-Mixtral-47B on OnePlus Ace 2, which can only place up to 25% of FFN weights in DRAM due to its relatively low available memory size.
\ Fig.6 illustrates the generation speeds for various models. On the high-end OnePlus 12, PowerInfer-2 achieves 3.94× (up to 4.38×) and 25.4× (up to 29.2×) speedup on average compared to LLMFlash and llama.cpp, respectively. For the mid-end OnePlus Ace 2, PowerInfer-2 achieves 2.99× speedup on average than LLMFlash and 13.3× speedup on average than llama.cpp.
\ When the model size is beyond available DRAM, model weights are swapping between flash storage and memory, introducing significant I/O overhead. Although LLMFlash employs a neuron cache to store recently accessed neurons
\ 
\ instead of directly using mmap, which makes it 5.35× faster than llama.cpp on average, about 10% of activated neurons still need to be loaded from flash in a blocking way, resulting in long delays before computations. In contrast, PowerInfer-2 not only utilizes an efficient neuron pipeline that overlaps I/O operations with computation, but also loading neurons with flexible bundles to improve the I/O throughput, which effectively eliminates this overhead and achieves better performance across different models.
\ As shown in Fig.6, the acceleration ratio of PowerInfer-2 varies with models. The variation is attributed to the actual number of activated parameters. For example, although TurboSparse-Mixtral-47B has 47 billion parameters, with the mixture-of-expert architecture and high sparsity, it only activates about 3B parameters for one token, which is close to that of TurboSparse-Mistral-7B. And that is the reason why these two models have similar performance. Notably, TurboSparseMixtral-47B achieves a generation speed of 9.96 tokens/s but still does not exhaust all available memory. By enlarging the neuron cache, the decoding speed can be further improved, which will be evaluated in later sections (§7.2.3). Llama-13B exhibits lower sparsity, which activates nearly 2× more parameters compared to TurboSparse-Mistral-7B, ending up with 2× slower than TurboSparse-Mistral-7B.
\ 7.2.2 Prefill Performance
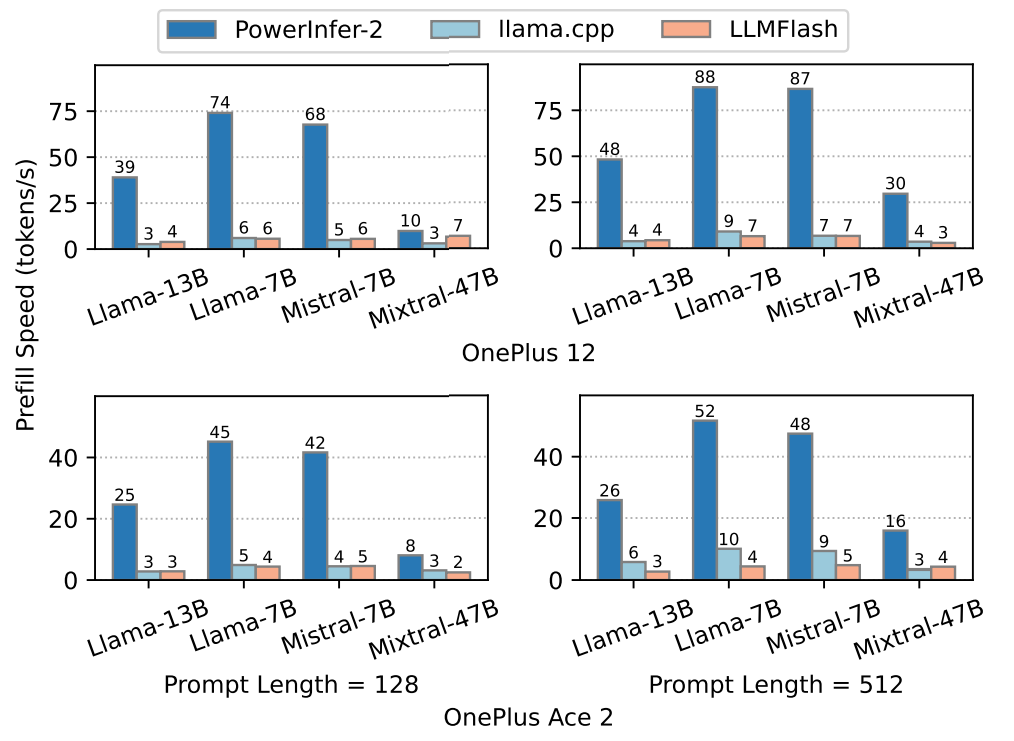
In this section, we evaluate the prefill performance of PowerInfer-2 at prompt lengths of 128 and 512 tokens. Fig.7 illustrates the prompt processing speeds of PowerInfer-2 and other baseline systems. For prompt length of 128 tokens, PowerInfer-2 is 6.95× faster than LLMFlash and 9.36× faster than llama.cpp on average on the high-end OnePlus 12, 7.15× and 6.61× faster on the mid-end OnePlus Ace 2. For prompt length of 512 tokens, the speedup of PowerInfer-2 reaches up to 13.3× compared to LLMFlash when running Llama-7B on OnePlus 12 with 2.5GB memory.
\ The speedup is attributed to PowerInfer-2’s choice to NPUcentric prefill. First, the NPU is more powerful than the CPU and GPU when performing computations of large batch sizes. The baseline systems use GPU in the prefill phase, while PowerInfer-2 takes full advantage of the NPU to accelerate the computation. Second, PowerInfer-2 fully utilizes sequential I/O at prefill stage. As the batch size gets larger, the probability of a single neuron being activated also increases. In TurboSparse-Mixtral-47B, with the batch size of 128, the probability of a neuron being activated would be 99.99%. Combining with the fact that sequential I/O is 4 GB/s, three times faster than random I/O, PowerInfer-2 uses dense computing at prefill stage, loading the whole FFN block into memory sequentially. Third, weight loading can be efficiently overlapped with the computation in PowerInfer-2 by prefetching weights of the next layer during the computation of the current layer.
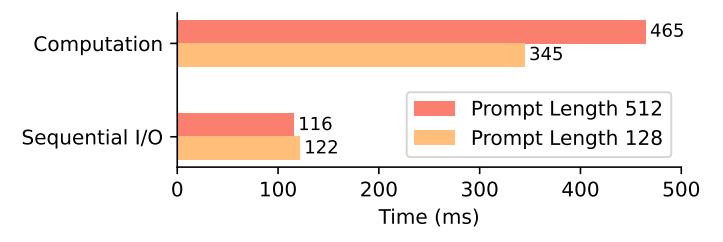
\ Taking advantages of all these techniques, the speed of computation, rather than the speed of sequential read, has become the bottleneck of PowerInfer-2 at prefill stage. As shown in Fig.8, the computation, which includes dequantization of weights and execution of operators, takes 2.83× time than sequential I/O at prompt length of 128 tokens. With prompt length of 512 tokens, the gap grows to 4× because the computation takes more time while sequential I/O remains the same.
\ 
\ 7.2.3 Performance with Various Memory Capacities
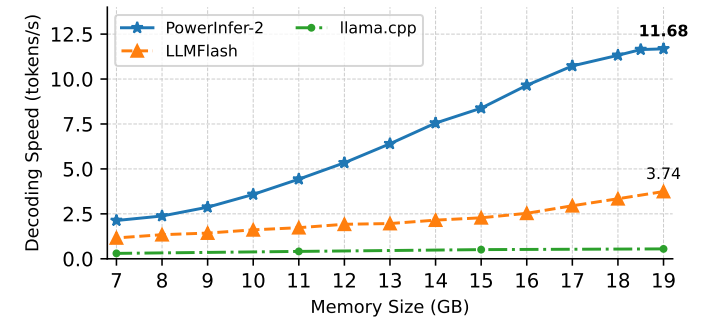
In the context of real-world usage, smartphones are tasked with running multiple applications simultaneously [1], resulting in varying available memory. To evaluate the adaptability of PowerInfer-2 under these conditions, we evaluate its performance across a range of memory capacities from 7GB to 19GB. Fig.9 presents the decoding speeds under different memory configurations for TurboSparse-Mixtral-47B.
\ When the available memory is limited to just 7GB, PowerInfer-2’s decoding speed is 2.13 tokens/s. By design, non-FFN layer weights[5] (1GB), predictor weights (2.6GB) and FFN weights’ quantization scales (2.7GB) are resident in
\ 
\ 
\ memory, and 300MB memory is reserved for intermediate tensors, KV cache, and other runtime memory of PowerInfer-2, resulting in 6.6GB memory used in total. Given the overall limitation of 7GB, the size of the neuron cache that stores FFN weights is set to 400MB, which only caches 1.8% of FFN weights of TurboSparse-Mixtral-47B. Such a small cache renders reusing cached neuron among tokens nearly impossible. Therefore all neurons have to be fetched from flash storage for each token. Nevertheless, PowerInfer-2 still performs 1.84× faster than LLMFlash due to efficient flexible neuron loading and neuron-level pipeline. PowerInfer-2’s decoding speed scales linearly with the memory size up to 18GB memory size, as the I/O is the bottleneck and the required I/O operations are reduced almost linearly with the increase in neuron cache size. Notably, when using up all available memory (19GB), PowerInfer-2 achieves a decoding speed of 11.68 tokens/s, which is 3.12× faster than LLMFlash and 21.2× faster than llama.cpp.
\ 7.2.4 Decoding Speed Distribution
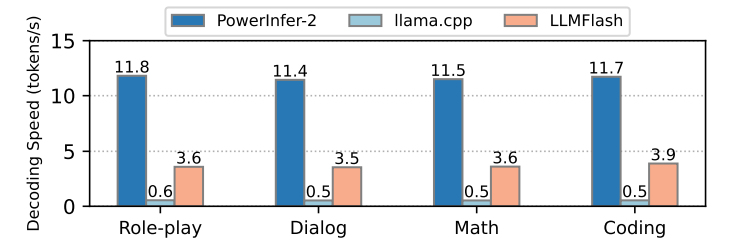
To evaluate the robustness of PowerInfer-2 in different practical LLM tasks, we investigate the distribution of decoding speeds of PowerInfer-2 at both task-level and token-level.
\ For task-specific decoding, we measure the average decoding speeds for four representative real-world tasks: role-play, multi-turn dialogue, math problem solving, and code generation. Fig.10 shows that PowerInfer-2 consistently achieves at least 11.4 tokens/s decoding speed across different tasks, which demonstrates the robustness of PowerInfer-2 in handling diverse tasks. The decoding speed differs slightly due to the fact that the activation sparsity of the model varies when
\ 
\ performing different tasks.
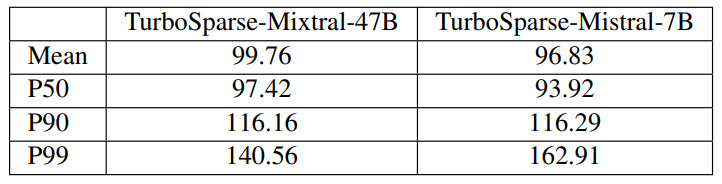
\ To examine the distribution of per-token decoding speeds, we measured the average, 50th percentile (P50), 90th percentile (P90), and 99th percentile (P99) decoding speeds of 1,024 tokens on the TurboSparse-Mixtral-47B and TurboSparse-Mistral-7B. We constrained both models to place only 50% of FFN weights in DRAM. Table 4 illustrates the decoding speed distribution. For the TurboSparseMixtral-47B, 10% of tokens are generated 16.5% slower than the average decoding speed, and the 99th percentile decoding latency is 40.9% slower than the average latency. This performance variation is caused by varying activation similarities of neighboring tokens. Tokens with similar activations can share commonly activated neurons already resident in the neuron cache, reducing the need for I/O to fetch neurons from the flash storage. Taking TurboSparse-Mixtral-47B as an example, we observed that the average per-token neuron cache miss rate is 3.5%, while the P99 miss rate is 18.9%, which is 5.4× higher than the average. It indicates that activation similarities differs greatly among tokens. Higher miss rates result in more neurons being swapped between the neuron cache and the flash storage, and thus longer decoding time.
\
7.3 In-Memory Performance
If the model size fits entirely within the device’s memory, PowerInfer-2 can save memory usage while maintaining a high decoding speed. This section evaluates the decoding performance of TurboSparse-Mistral-7B when sufficient memory is available. We compare PowerInfer-2 with llama.cpp and MLC-LLM, which exemplify CPU and GPU decoding on smartphones, respectively. The results are illustrated in Fig.11.
\ When no offloading is used and thus all model weights are resident in memory, PowerInfer-2 is 1.64× and 2.06× faster than llama.cpp and MLC-LLM on average, respectively. This is mainly attributed to the benefit of model’s activation sparsity, which reduces about 70% percent of FFN computations. TurboSparse-Mistral-7B requires at least 4GB memory to store all of its model parameters. By offloading half of the FFN weights, PowerInfer-2 can save approximately 1.5GB of memory, achieving nearly 40% in memory savings while maintaining comparable performance to llama.cpp and MLCLLM, which do not offload any weights. By contrast, offloading such amount of FFN weights deteriorates llama.cpp’s decoding performance by 20.8×, and even makes MLC-LLM fail to run. It demonstrates that PowerInfer-2 is capable of
\ 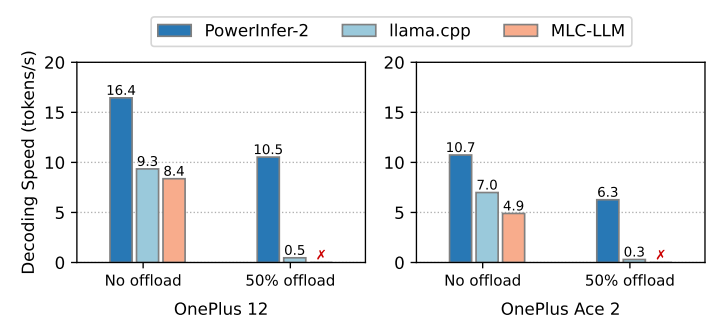
\ effectively reducing memory consumption for models that are already fit in memory and maintaining the user experience at the same time.
\
:::info Authors:
(1) Zhenliang Xue, Co-first author from Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(2) Yixin Song, Co-first author from Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(3) Zeyu Mi, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University (yzmizeyu@sjtu.edu.cn);
(4) Le Chen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(5) Yubin Xia, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University;
(6) Haibo Chen, Institute of Parallel and Distributed Systems (IPADS), Shanghai Jiao Tong University.
:::
:::info This paper is available on arxiv under CC BY 4.0 license.
:::
[3] https://huggingface.co/PowerInfer/TurboSparse-MistralInstruct
\ [4] https://huggingface.co/PowerInfer/TurboSparse-Mixtral
\ [5] Including token embeddings, self-attention layers, and the final output projection.
You May Also Like

The Channel Factories We’ve Been Waiting For


American Bitcoin’s $5B Nasdaq Debut Puts Trump-Backed Miner in Crypto Spotlight
