

5 façons surprenantes dont l'IA d'aujourd'hui échoue à réellement "penser"

Les grands modèles de langage (LLMs) ont connu une explosion de capacités, montrant des performances remarquables dans des tâches allant de la compréhension du langage naturel à la génération de code. Nous interagissons avec eux quotidiennement, et leur fluidité peut être étonnante, nous plaçant carrément dans une vallée dérangeante de l'intelligence artificielle. Mais cette performance sophistiquée équivaut-elle à une véritable pensée, ou n'est-ce qu'une illusion high-tech ?
\ Un nombre croissant de recherches suggère que derrière le rideau de compétence se cache un ensemble de limitations profondes et contre-intuitives. Cet article explore cinq des échecs les plus significatifs qui exposent le gouffre entre la performance de l'IA et la véritable compréhension humaine.
Ils ne raisonnent pas plus fort ; ils s'effondrent simplement
Un article récent d'Apple Research, intitulé "L'illusion de la pensée", révèle une faille critique même dans les "Modèles de raisonnement larges" (LRMs) les plus avancés qui utilisent des techniques comme la chaîne de pensée. La recherche montre que ces modèles ne raisonnent pas vraiment mais sont des simulateurs sophistiqués qui se heurtent à un mur lorsque les problèmes deviennent suffisamment complexes.
\ Les chercheurs ont utilisé le puzzle de la Tour de Hanoï pour tester les modèles, identifiant trois régimes de performance distincts basés sur la complexité du puzzle :
\
- Faible complexité (3 disques) : Les modèles standard, sans raisonnement, ont performé aussi bien, voire mieux, que les modèles LRM "pensants".
- Complexité moyenne (6 disques) : Les LRMs qui génèrent une chaîne de pensée plus longue ont montré un avantage clair.
- Haute complexité (7+ disques) : Les deux types de modèles ont connu un "effondrement complet", leur précision chutant à zéro.
\
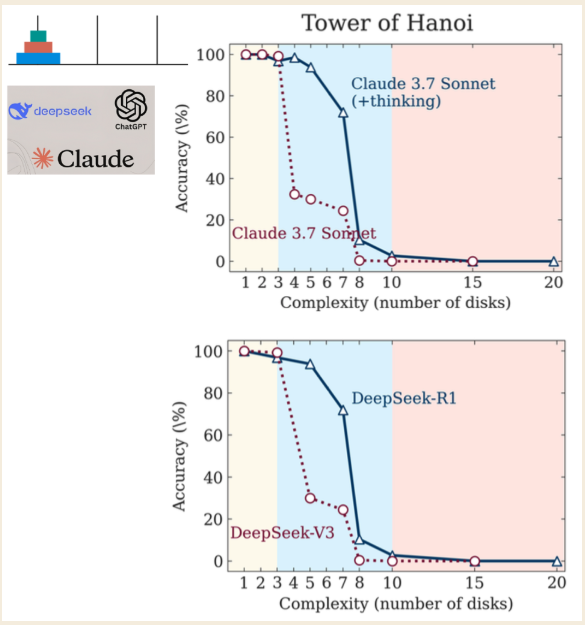
La découverte la plus contre-intuitive était que les modèles "pensent" moins à mesure que les problèmes deviennent plus difficiles. Plus accablant encore, ils échouent à calculer correctement même lorsqu'on leur donne explicitement les algorithmes nécessaires pour résoudre le puzzle. Cela suggère une incapacité fondamentale à appliquer des règles sous pression, une imitation creuse de la pensée qui se brise quand c'est le plus important. (Les chercheurs notent que bien qu'Anthropic, un laboratoire d'IA rival, ait soulevé des objections, elles restent des chicanes mineures plutôt qu'une réfutation fondamentale des résultats.)
\ Comme le disent les chercheurs de l'Université d'Arizona, ce comportement capture l'essence de l'illusion :
...suggérant que les LLMs ne sont pas des raisonneurs de principe mais plutôt des simulateurs sophistiqués de texte ressemblant à du raisonnement.
Leur "Chaîne de pensée" est souvent un mirage
La Chaîne de pensée (CoT) est le processus par lequel un LLM écrit son raisonnement étape par étape avant de livrer une réponse finale, une fonctionnalité conçue pour améliorer la précision et révéler sa logique interne. Cependant, une étude récente analysant comment les LLMs gèrent l'arithmétique de base montre que ce processus est souvent un "mirage fragile".
\ De façon surprenante, il existe de vastes incohérences entre les étapes de raisonnement dans la CoT et la réponse finale que le modèle fournit. Dans des tâches impliquant une simple addition, une découverte choquante a été faite : dans plus de 60% des échantillons, le modèle a produit des étapes de raisonnement incorrectes qui, mystérieusement, ont conduit à la bonne réponse finale.
\ C'est l'équivalent d'un étudiant montrant un travail insensé sur un test de mathématiques mais écrivant miraculeusement le bon nombre final. Vous ne concluriez pas qu'il comprend la matière ; vous soupçonneriez qu'il a copié la réponse. En IA, cela suggère que le "raisonnement" est souvent une justification post-hoc, pas un véritable processus de pensée. Ce n'est pas un bug qui se corrige en augmentant l'échelle ; le problème s'aggrave avec des modèles plus avancés, le taux de ce comportement contradictoire augmentant à 74% sur GPT-4.
\ Si le "processus de pensée" interne du modèle est un mirage, que se passe-t-il lorsqu'il est forcé de résoudre un problème réel et complexe ? Souvent, il sombre dans la folie.
Ils sont piégés dans des boucles de "descente dans la folie"
Lors de l'utilisation des LLMs pour des tâches complexes comme le débogage de code, un schéma dangereux peut émerger : une "descente dans la folie" ou une "boucle d'hallucination". C'est un cycle de rétroaction où un LLM, tentant de corriger une erreur de programmation, se retrouve piégé dans une boucle irrationnelle sans fin. Il suggère une correction d'apparence plausible qui échoue, et lorsqu'on lui demande une autre solution, réintroduit souvent l'erreur originale, piégeant l'utilisateur dans un cycle stérile.
\ Une étude qui a chargé des programmeurs de déboguer du code a révélé une tendance explosive pour les flux de travail assistés par l'IA. Les résultats étaient clairs : les programmeurs non assistés par l'IA ont résolu plus de tâches correctement et moins de tâches incorrectement que le groupe qui a utilisé les LLMs pour obtenir de l'aide.
\ Laissez cela vous pénétrer : dans une tâche de débogage complexe, avoir un assistant IA de pointe n'était pas seulement inutile—c'était activement nuisible, conduisant à des résultats pires que de ne pas avoir d'IA du tout. Les participants utilisant l'IA se sont fréquemment retrouvés coincés dans ces boucles stériles, perdant du temps sur des corrections conceptuellement sans fondement. Les chercheurs ont également identifié le problème de la "solution bruyante", où une correction correcte est enfouie dans une multitude de suggestions non pertinentes, une recette parfaite pour la frustration humaine. Cette "assistance" défectueuse souligne comment le vernis impressionnant de l'IA peut cacher un noyau profondément peu fiable, surtout lorsque les enjeux sont élevés.
Leurs benchmarks impressionnants sont construits sur une base de défauts
Lorsque les entreprises d'IA publient de nouveaux modèles, elles pointent vers des scores de benchmark impressionnants pour prouver leur supériorité. Un examen plus approfondi peut cependant révéler une image beaucoup moins flatteuse.
\ Le SWE-bench (Software Engineering Benchmark), utilisé pour mesurer la capacité d'un LLM à résoudre des problèmes logiciels réels de GitHub, est une étude de cas exemplaire. Une étude indépendante de l'Université de York a trouvé des défauts critiques qui ont considérablement gonflé les capacités perçues des modèles :
\
- Fuite de solution ("Triche") : Dans 32,67% des correctifs réussis, la solution correcte était déjà fournie dans le rapport de problème lui-même.
- Tests faibles : Dans 31,08% des cas où le modèle a "réussi", les tests de vérification étaient trop faibles pour confirmer réellement que la correction était correcte.
\ Lorsque ces instances défectueuses ont été filtrées, la performance réelle d'un modèle de premier plan (SWE-Agent + GPT-4) s'est effondrée. Son taux de résolution est passé d'un 12,47% annoncé à seulement 3,97%. De plus, plus de 94% des problèmes dans le benchmark ont été créés avant les dates limites de connaissance des LLMs, soulevant de sérieuses questions sur la fuite de données.
\ Cela révèle une réalité troublante : les benchmarks sont souvent des outils marketing qui présentent un scénario idéal, cultivé en laboratoire, qui s'effondre sous l'examen du monde réel. L'écart entre la puissance annoncée et la performance vérifiée n'est pas une fissure ; c'est un canyon.
Ils maîtrisent les règles mais manquent fondamentalement de compréhension
Même si tous les échecs techniques ci-dessus étaient corrigés, une barrière plus profonde et plus philosophique demeure. Les LLMs manquent des composantes essentielles de l'intelligence humaine. Alors que les philosophes discutent de la conscience et de l'intentionnalité, de nombreux arguments suggèrent que la rationalité, c'est-à-dire notre capacité à saisir des concepts universels et à raisonner logiquement, est l'aspect clé unique aux humains et absent dans l'IA.
\ Cette idée est renforcée par le physicien Roger Penrose, qui utilise le théorème d'incomplétude de Gödel pour argumenter que la compréhension mathématique humaine transcende tout ensemble fixe de règles algorithmiques. Pensez à n'importe quel algorithme comme un manuel de règles fini. Le théorème de Gödel montre qu'un mathématicien humain peut toujours regarder le manuel de l'extérieur et comprendre des vérités que le manuel lui-même ne peut pas prouver.
\ Nos esprits ne suivent pas simplement les règles du livre ; nous pouvons lire tout le livre et saisir ses limites. Cette capacité d'insight, cette compréhension "non calculable", est ce qui sépare la cognition humaine de l'IA même la plus avancée.
\ Les LLMs sont des maîtres dans la manipulation de symboles basés sur des algorithmes et des modèles statistiques. Ils ne possèdent cependant pas la conscience requise pour une véritable compréhension. Comme le conclut un argument puissant :
Le tour du magicien
Bien que les LLMs soient indéniablement des outils puissants qui peuvent simuler un comportement intelligent avec une précision troublante, les preuves croissantes montrent qu'ils sont davantage comme des simulateurs sophistiqués que de véritables penseurs. Leur performance est une grande illusion, un spectacle éblouissant de compétence qui s'effondre sous la pression, contredit sa propre logique et s'appuie sur des métriques défectueuses. C'est comparable à un tour de magicien (apparemment impossible), mais finalement une illusion construite sur des techniques astucieuses, pas de la vraie magie. Alors que nous continuons à intégrer ces systèmes dans notre monde, nous devons rester critiques et poser la question essentielle :
\ Si ces machines d'IA s'effondrent sur des problèmes plus difficiles, même lorsque vous leur donnez les algorithmes et les règles, pensent-elles réellement ou font-elles simplement très bien semblant ?
Podcast :
\
- Apple : ICI
- Spotify : ICI
\


Vous aimerez peut-être aussi

Les pourparlers de cessez-le-feu Pakistan-Iran renforcent l'optimisme du marché du 15 avril

La Fondation Solana renforce sa sécurité avec STRIDE après une exploitation de 285 millions de dollars




