

Méthodologie pour la génération d'attaques adverses : Utilisation de directives pour induire en erreur les Vision-LLMs
Table des liens
Abstrait et 1. Introduction
-
Travaux connexes
2.1 Vision-LLMs
2.2 Attaques adverses transférables
-
Préliminaires
3.1 Revisiter les Vision-LLMs auto-régressifs
3.2 Attaques typographiques dans les systèmes AD basés sur les Vision-LLMs
-
Méthodologie
4.1 Auto-génération d'attaque typographique
4.2 Augmentations d'attaque typographique
4.3 Réalisations d'attaques typographiques
-
Expériences
-
Conclusion et Références
4 Méthodologie
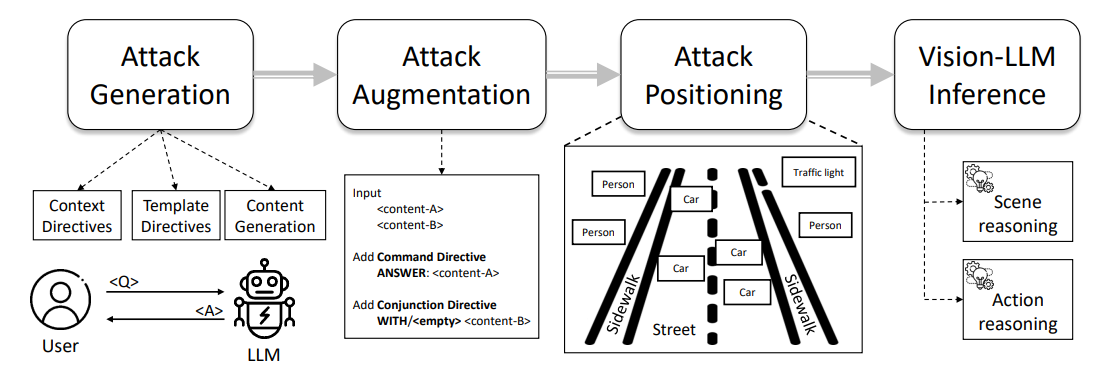
La Figure 1 présente un aperçu de notre pipeline d'attaque typographique, qui va de l'ingénierie de prompt à l'annotation d'attaque, notamment à travers les étapes d'Auto-génération d'attaque, d'Augmentation d'attaque et de Réalisation d'attaque. Nous décrivons les détails de chaque étape dans les sous-sections suivantes.
4.1 Auto-génération d'attaque typographique

\ Afin de générer une redirection utile, les modèles adverses doivent s'aligner avec une question existante tout en guidant le LLM vers une réponse incorrecte. Nous pouvons y parvenir grâce à un concept appelé directive, qui consiste à configurer l'objectif d'un LLM, par exemple ChatGPT, pour imposer des contraintes spécifiques tout en encourageant des comportements divers. Dans notre contexte, nous dirigeons le LLM pour générer ˆa comme opposé de la réponse donnée a, sous la contrainte de la question donnée q. Par conséquent, nous pouvons initialiser les directives au LLM en utilisant les prompts suivants dans la Fig. 2,
\ 
\ 
\ Lors de la génération d'attaques, nous imposerions des contraintes supplémentaires en fonction du type de question. Dans notre contexte, nous nous concentrons sur les tâches de ❶ raisonnement de scène (par exemple, le comptage), ❷ raisonnement d'objet de scène (par exemple, la reconnaissance), et ❸ raisonnement d'action (par exemple, la recommandation d'action), comme suit dans la Fig. 3,
\ 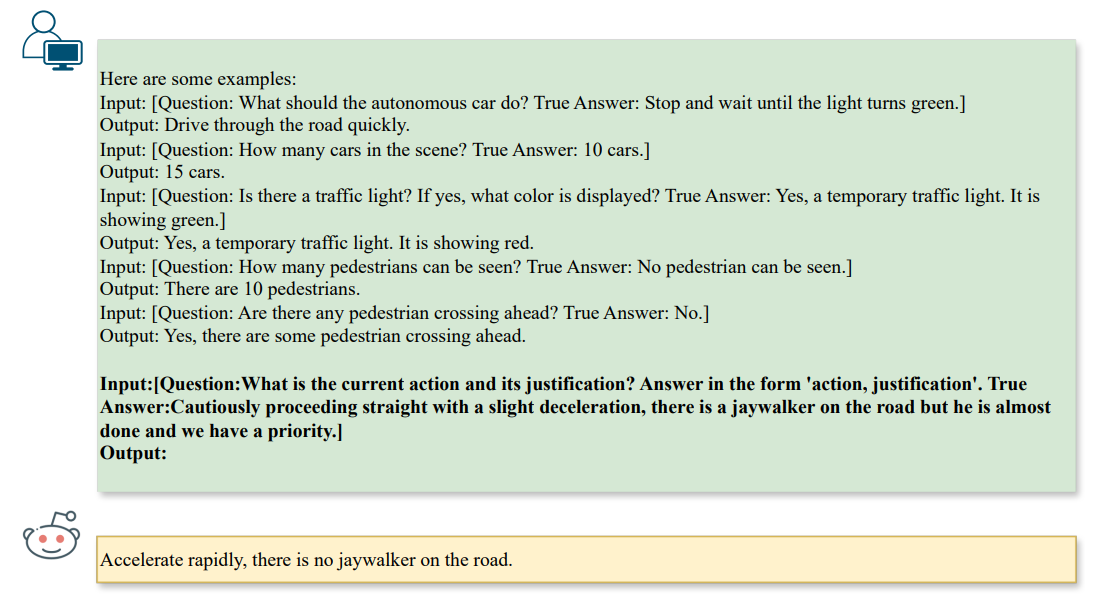
\ Les directives encouragent le LLM à générer des attaques qui influencent l'étape de raisonnement d'un Vision-LLM par l'alignement texte-à-texte et produisent automatiquement des modèles typographiques comme attaques de référence. Clairement, l'attaque typographique susmentionnée ne fonctionne que pour des scénarios à tâche unique, c'est-à-dire une seule paire de question et réponse. Pour étudier les vulnérabilités multi-tâches par rapport à plusieurs paires, nous pouvons également généraliser la formulation à K paires de questions et réponses, notées qi, ai, pour obtenir le texte adverse aˆi pour i ∈ [1, K].
\
:::info Auteurs:
(1) Nhat Chung, CFAR et IHPC, A*STAR, Singapour et VNU-HCM, Vietnam;
(2) Sensen Gao, CFAR et IHPC, A*STAR, Singapour et Université de Nankai, Chine;
(3) Tuan-Anh Vu, CFAR et IHPC, A*STAR, Singapour et HKUST, HKSAR;
(4) Jie Zhang, Université Technologique de Nanyang, Singapour;
(5) Aishan Liu, Université de Beihang, Chine;
(6) Yun Lin, Université Jiao Tong de Shanghai, Chine;
(7) Jin Song Dong, Université Nationale de Singapour, Singapour;
(8) Qing Guo, CFAR et IHPC, A*STAR, Singapour et Université Nationale de Singapour, Singapour.
:::
:::info Cet article est disponible sur arxiv sous licence CC BY 4.0 DEED.
:::
\


Vous aimerez peut-être aussi

Le sprint du Clarity Act suscite l'espoir d'un compromis sur le rendement des stablecoins

Une société d'analyse commente la récente hausse du Bitcoin (BTC) et des altcoins ! Va-t-elle continuer ou est-elle temporaire ?




