

Comment le Mélange d'Adaptations Rend le Fine-Tuning des Modèles de Langage Moins Coûteux et Plus Intelligent
Table des Liens
Abstrait et 1. Introduction
-
Contexte
2.1 Mélange d'experts
2.2 Adaptateurs
-
Mélange d'adaptations
3.1 Politique de routage
3.2 Régularisation de cohérence
3.3 Fusion de modules d'adaptation et 3.4 Partage de modules d'adaptation
3.5 Connexion aux réseaux neuronaux bayésiens et à l'ensemble de modèles
-
Expériences
4.1 Configuration expérimentale
4.2 Résultats clés
4.3 Étude d'ablation
-
Travaux connexes
-
Conclusions
-
Limitations
-
Remerciements et références
Annexe
A. Ensembles de données NLU à quelques exemples B. Étude d'ablation C. Résultats détaillés sur les tâches NLU D. Hyper-paramètre
3 Mélange d'adaptations

\
3.1 Politique de routage
Des travaux récents comme THOR (Zuo et al., 2021) ont démontré que la politique de routage stochastique comme le routage aléatoire fonctionne aussi bien que le mécanisme de routage classique comme le routage Switch (Fedus et al., 2021) avec les avantages suivants. Comme les exemples d'entrée sont acheminés aléatoirement vers différents experts, il n'y a pas besoin d'équilibrage de charge supplémentaire car chaque expert a une chance égale d'être activé, ce qui simplifie le cadre. De plus, il n'y a pas de paramètres ajoutés, et donc pas de calcul supplémentaire, au niveau de la couche Switch pour la sélection d'experts. Ce dernier point est particulièrement important dans notre contexte pour un réglage fin efficace en termes de paramètres afin de maintenir les paramètres et les FLOPs identiques à ceux d'un seul module d'adaptation. Pour analyser le fonctionnement d'AdaMix, nous démontrons les connexions entre le routage stochastique et la moyenne des poids du modèle avec les réseaux neuronaux bayésiens et l'ensemble de modèles dans la section 3.5.
\ \ 
\ \ Ce routage stochastique permet aux modules d'adaptation d'apprendre différentes transformations pendant l'entraînement et d'obtenir plusieurs vues de la tâche. Cependant, cela crée également un défi quant aux modules à utiliser pendant l'inférence en raison du protocole de routage aléatoire pendant l'entraînement. Nous relevons ce défi avec les deux techniques suivantes qui nous permettent en outre de regrouper les modules d'adaptation et d'obtenir le même coût de calcul (FLOPs, paramètres d'adaptation ajustables) que celui d'un seul module.
3.2 Régularisation de cohérence
\ 
\ \ \ 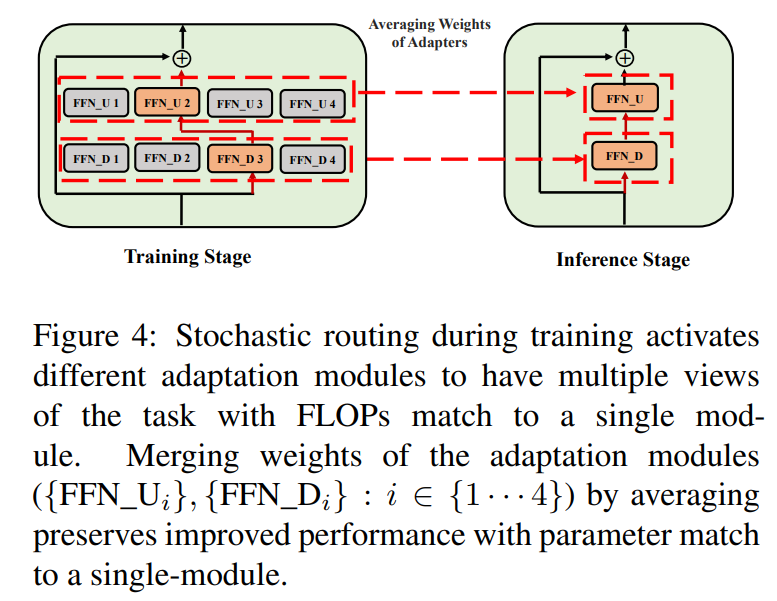
3.3 Fusion de modules d'adaptation
Bien que la régularisation ci-dessus atténue l'incohérence dans la sélection aléatoire des modules pendant l'inférence, elle entraîne toujours un coût de service accru pour héberger plusieurs modules d'adaptation. Des travaux antérieurs sur le réglage fin des modèles de langage pour les tâches en aval ont montré une amélioration des performances en moyennant les poids de différents modèles affinés avec différentes graines aléatoires, surpassant un seul modèle affiné. Des travaux récents (Wortsman et al., 2022) ont également montré que des modèles affinés différemment à partir de la même initialisation se trouvent dans le même bassin d'erreur, ce qui motive l'utilisation de l'agrégation de poids pour une synthèse robuste des tâches. Nous adoptons et étendons les techniques antérieures pour le réglage fin des modèles de langage à notre entraînement efficace en paramètres des modules d'adaptation multi-vues
\ \ 
\
3.4 Partage de modules d'adaptation
\ 
3.5 Connexion aux réseaux neuronaux bayésiens et à l'ensemble de modèles
\ 
\ \ Cela nécessite de faire la moyenne sur tous les poids de modèle possibles, ce qui est impossible en pratique. Par conséquent, plusieurs méthodes d'approximation ont été développées basées sur des méthodes d'inférence variationnelle et des techniques de régularisation stochastique utilisant des abandons (dropouts). Dans ce travail, nous utilisons une autre régularisation stochastique sous forme de routage aléatoire. Ici, l'objectif est de trouver une distribution de substitution qθ(w) dans une famille de distributions traitable qui peut remplacer le vrai postérieur du modèle qui est difficile à calculer. Le substitut idéal est identifié en minimisant la divergence de Kullback-Leibler (KL) entre le candidat et le vrai postérieur.
\ \ 
\ \ \ 
\ \ \ 
\ \ \ \
:::info Auteurs:
(1) Yaqing Wang, Purdue University (wang5075@purdue.edu);
(2) Sahaj Agarwal, Microsoft (sahagar@microsoft.com);
(3) Subhabrata Mukherjee, Microsoft Research (submukhe@microsoft.com);
(4) Xiaodong Liu, Microsoft Research (xiaodl@microsoft.com);
(5) Jing Gao, Purdue University (jinggao@purdue.edu);
(6) Ahmed Hassan Awadallah, Microsoft Research (hassanam@microsoft.com);
(7) Jianfeng Gao, Microsoft Research (jfgao@microsoft.com).
:::
:::info Cet article est disponible sur arxiv sous licence CC BY 4.0 DEED.
:::
\


Vous aimerez peut-être aussi

« Un ouragan arrive » : Le Bitcoin pourrait chuter à 10 000 $ cette année, selon un analyste de Bloomberg

Déclaration de Trump sur les cryptomonnaies : Une analyse critique de l'impact sur le marché et du contexte politique




