

सिस्टम टेबल्स के बिना Databricks क्लस्टर लागत और उपयोग का अनुकूलन

अधिकांश एंटरप्राइज़ Databricks वातावरणों में (MSC या बड़े एनालिटिक्स इकोसिस्टम जैसे), सिस्टम टेबल जैसे system.job_run_logs या system.cluster_events सुरक्षा या गवर्नेंस नीतियों के कारण प्रतिबंधित या अक्षम हो सकती हैं।
हालांकि, क्लस्टर उपयोग और लागत की ट्रैकिंग महत्वपूर्ण है:
- जॉब कंप्यूट का कितनी कुशलता से उपयोग करते हैं यह समझने के लिए
- निष्क्रिय क्लस्टर या लागत रिसाव की पहचान करने के लिए
- इंफ्रास्ट्रक्चर बजट का पूर्वानुमान लगाने के लिए
- कस्टम लागत डैशबोर्ड बनाने के लिए
यह ब्लॉग केवल Databricks REST APIs का उपयोग करके क्लस्टर उपयोग और लागत की गणना के लिए एक चरण-दर-चरण दृष्टिकोण प्रदर्शित करता है — किसी सिस्टम टेबल की आवश्यकता नहीं।
प्रोजेक्ट यूज़ केस
हमारे MSC डेटा प्लेटफॉर्म में, हम डेवलपमेंट, टेस्ट और प्रोडक्शन में कई Databricks क्लस्टर चलाते हैं। \n हमारे पास तीन प्रमुख चुनौतियां थीं:
- सिस्टम टेबल तक कोई पहुंच नहीं (एडमिन नीतियों द्वारा प्रतिबंधित)
- ADF या ऑर्केस्ट्रेशन पाइपलाइन द्वारा डायनामिक रूप से बनाए गए जॉब के लिए एफेमरल क्लस्टर
- क्लस्टर उपयोग लागत में कैसे परिवर्तित होता है इसका कोई सीधा दृश्य नहीं
इसलिए, हमने एक लाइटवेट उपयोग विश्लेषक बनाया जो:
- Databricks REST APIs से डेटा पुल करता है
- जॉब रनटाइम बनाम क्लस्टर रनटाइम की गणना करता है
- DBU और VM दरों का उपयोग करके लागत का अनुमान लगाता है
- उपभोग में आसान DataFrame आउटपुट करता है
समस्या और दृष्टिकोण
पहचानी गई चुनौती
टीमों को अक्सर जानना आवश्यक है:
- कौन से क्लस्टर निष्क्रिय हैं (कम जॉब गतिविधि के साथ चल रहे हैं)?
- उपयोग % क्या है (जॉब रनटाइम बनाम क्लस्टर अपटाइम)?
- प्रत्येक क्लस्टर पर कितनी लागत आ रही है (DBU + VM)?
जब Unity Catalog सिस्टम टेबल (जैसे, system.job_run_logs) अनुपलब्ध हों, तो डिफ़ॉल्ट SQL-आधारित दृष्टिकोण विफल हो जाता है। REST API विश्वसनीय फॉलबैक बन जाता है।
नोटबुक में उपयोग किया गया उच्च-स्तरीय दृष्टिकोण
- /api/2.0/clusters/list के माध्यम से क्लस्टर सूचीबद्ध करें।
- क्लस्टर JSON (created/start/terminated फ़ील्ड) के अंदर टाइमस्टैम्प का उपयोग करके क्लस्टर अपटाइम का अनुमान लगाएं। (जब /clusters/events अनुपलब्ध हो तो यह एक व्यावहारिक फॉलबैक है।)
- समय फ़िल्टर (या सीमा) के साथ /api/2.1/jobs/runs/list का उपयोग करके हाल के जॉब रन प्राप्त करें।
- cluster_instance.cluster_id (या अन्य क्लस्टर मेटाडेटा) का उपयोग करके जॉब रन को क्लस्टर से मिलाएं।
- उपयोग की गणना करें: उपयोग % = total_job_runtime / total_cluster_uptime।
- एक सरल सूत्र का उपयोग करके लागत का अनुमान लगाएं: लागत = running_hours × (DBU/hr × assumed DBU) + running_hours × nodes × VM $/hr।
यह नोटबुक जानबूझकर बाउंडेड क्वेरी (अंतिम N रन, समय विंडो) का उपयोग करती है ताकि यह तेज़ी से चले।
\ 1. सेटअप और कॉन्फ़िगरेशन
# Databricks Cluster Utilization & Cost Analyzer (no system tables) # Author: GPT-5 | Works on any workspace with REST API access # Requirements: Databricks Personal Access Token, Workspace URL # You can run this inside a Databricks notebook or externally. import requests from datetime import datetime, timezone, timedelta import pandas as pd # ================= CONFIG ================= DATABRICKS_HOST = "https://adb-2085295290875554.14.azuredatabricks.net/" # Replace with your workspace URL # DATABRICKS_TOKEN = "" # Replace with your PAT HEADERS = {"Authorization": f"Bearer {token}"} params={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} # Time window (e.g., last 7 days) DAYS_BACK = 7 SINCE_TS_MS = int((datetime.now(timezone.utc) - timedelta(days=DAYS_BACK)).timestamp() * 1000) UNTIL_TS_MS = int(datetime.now(timezone.utc).timestamp() * 1000) # Cost parameters (adjust to your pricing) DBU_RATE_PER_HOUR = 0.40 # $ per DBU/hr VM_COST_PER_NODE_PER_HOUR = 0.60 # $ per cloud VM node/hr DEFAULT_DBU_PER_CLUSTER_PER_HOUR = 8 # Typical for small-medium jobs cluster # ==========================================
\ यह सेक्शन इनिशियलाइज़ करता है:
- प्रमाणीकरण के लिए वर्कस्पेस URL और टोकन
- समय सीमा जिसके लिए आप उपयोग का विश्लेषण करना चाहते हैं
- लागत धारणाएं:
- DBU दर ($/hr प्रति DBU)
- VM नोड लागत
- अनुमानित DBU खपत
एंटरप्राइज़ सेटअप में, इन दरों को आपके FinOps या billing APIs के माध्यम से डायनामिक रूप से प्राप्त किया जा सकता है।
-
API रैपर फ़ंक्शन
\
# Api GET request def api_get(path, params=None): url = f"{DATABRICKS_HOST.rstrip('/')}{path}" try: r = requests.get(url, headers=HEADERS, params=params, timeout=60) if r.status_code == 404: print(f"Skipping :{path} (404 Not Found)") return {} r.raise_for_status() return r.json() except Exception as e: print(f"Error: {e}") return {}
\ यह हेल्पर फ़ंक्शन सभी REST API GET कॉल को मानकीकृत करता है। \n यह:
-
पूर्ण एंडपॉइंट URL बनाता है
-
404 को सुचारू रूप से संभालता है (जब क्लस्टर या रन समाप्त हो गए हों तो महत्वपूर्ण)
-
पार्स किया गया JSON रिटर्न करता है
यह क्यों महत्वपूर्ण है: यह फ़ंक्शन क्लीन API संचार सुनिश्चित करता है यदि कोई क्लस्टर डेटा गायब है तो आपके नोटबुक फ्लो को तोड़े बिना।
\
-
सभी सक्रिय क्लस्टर सूचीबद्ध करें
\
# ---------- STEP 1: Get All Clusters Related Details ---------- def list_clusters(): clusters = [] res = api_get("/api/2.0/clusters/list") return res.get("clusters", [])
\ यह आपके वर्कस्पेस में उपलब्ध सभी क्लस्टर प्राप्त करता है। \n यह आपके "Compute" टैब को प्रोग्रामेटिक रूप से देखने के बराबर है। \n प्रतिक्रिया में शामिल है:
-
क्लस्टर ID
-
नाम
-
नोड काउंट
-
निर्माता जानकारी
-
निर्माण और समाप्ति समय
उपयोग का मामला: चयनित विंडो में कौन से क्लस्टर संसाधनों का उपभोग कर रहे हैं की पहचान करने में मदद करता है।
4. क्लस्टर रनटाइम का अनुमान लगाएं
\
# ---------- STEP 2: Get Cluster Events Runtime ---------- def get_cluster_runtime(cluster): events = [] offset = 0 limit = 200 # while True: # params = {"cluster_id": cluster_id} created = cluster.get("creator_user_name") created_time = cluster.get("start_time") or cluster.get("created_time") terminated_time = cluster.get("terminated_time") if not created_time: return 0 end_ts = terminated_time or UNTIL_TS_MS start_ms = max(created_time, SINCE_TS_MS) runtime_ms = max(0, end_ts - start_ms) return runtime_ms /1000/3600
\ हम प्रत्येक क्लस्टर के लिए कुल चलने के घंटे की गणना करते हैं:
-
निर्माण और समाप्ति टाइमस्टैम्प का उपयोग करता है
-
वर्तमान में चल रहे क्लस्टर को संभालता है (terminated_time गायब)
-
घंटों में सामान्यीकृत करता है
यह क्यों महत्वपूर्ण है: यह मूल्य उपयोग के लिए भाजक है — विंडो के दौरान कुल क्लस्टर अपटाइम का प्रतिनिधित्व करता है।
5. हाल के जॉब रन प्राप्त करें
\
# ------------------Get Recent Job Runs ---------------------------- def get_recent_job_runs(): params ={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} res = api_get("/api/2.1/jobs/runs/list", params) return res.get("runs", [])
\ संपूर्ण जॉब इतिहास प्राप्त करने के बजाय (जो धीमा है), \n यह फ़ंक्शन त्वरित निदान के लिए सबसे हाल के 10 जॉब रन प्राप्त करता है।
प्रोडक्शन में, आप इसके द्वारा फ़िल्टर कर सकते हैं:
- विशिष्ट job_id
- completed_only=true
- तिथि विंडो (start_time_from, start_time_to)
\
-
उपयोग और लागत की गणना करें
\
# -------------------------------------Compute Cost and parse cluster utilization detials --------------------- def compute_utilization_and_cost(clusters, job_runs): records =[] now_ms = int(datetime.now(timezone.utc).timestamp() * 1000) for c in clusters: cid = c.get("cluster_id") cname = c.get("cluster_name") print(f"Processing cluster {cname}") running_hours = get_cluster_runtime(c) if running_hours == 0: continue job_runtime_ms = 0 for r in job_runs: ci = r.get("cluster_instance",{}) if ci.get("cluster_id") == cid: s = r.get("start_time") or SINCE_TS_MS e = r.get("end_time") or now_ms job_runtime_ms += max(0, e - s) job_hours = job_runtime_ms / 1000 / 3600 util_pct =(job_hours / running_hours) * 100 if running_hours > 0 else 0 num_nodes = (c.get("num_workers") or c.get("autoscale",{}).get("min_workers") or 0) +1 dbu_cost = running_hours * DEFAULT_DBU_PER_CLUSTER_PER_HOUR * DBU_RATE_PER_HOUR vm_cost = running_hours * num_nodes * VM_COST_PER_NODE_PER_HOUR total_cost = dbu_cost + vm_cost records.append({ "cluster_id": cid, "cluster_name": cname,"running_hours":round(running_hours,2), "job_hours": round(job_hours,2) ,"utilization_pct": round(util_pct,2), "nodes": num_nodes,"dbu_cost": round(dbu_cost,2), "vm_cost": round(vm_cost,2), "total_cost": round(total_cost,2) }) return pd.DataFrame(records)
यह लॉजिक का केंद्र है:
-
प्रत्येक क्लस्टर के माध्यम से लूप करता है
-
प्रति क्लस्टर कुल जॉब रनटाइम की गणना करता है (जॉब रन API का उपयोग करके)
-
उपयोग प्रतिशत = (job_hours / cluster_running_hours) × 100 प्राप्त करता है
-
लागत का अनुमान लगाएं:
- दर × DBU/hr के आधार पर DBU लागत
- VM लागत = node_count × node_cost/hr × running_hours
यह क्यों महत्वपूर्ण है: \n यह दक्षता और व्यय की एक एकीकृत तस्वीर देता है — उच्च लागत लेकिन कम उपयोग वाले क्लस्टर की पहचान करने के लिए उपयोगी।
7. पाइपलाइन को ऑर्केस्ट्रेट करें
\
# ---------- MAIN ---------- print(f"Collecting data for last {DAYS_BACK} days...") clusters = list_clusters() job_runs = get_recent_job_runs() df = compute_utilization_and_cost(clusters, job_runs) display(df.sort_values("utilization_pct", ascending=False))
\ यह अंतिम ब्लॉक:
-
डेटा पुनर्प्राप्त करता है
-
लागत गणना करता है
-
सॉर्ट किए गए DataFrame को प्रदर्शित करता है
व्यवहार में, यह DataFrame हो सकता है:
-
Excel या Delta Table में एक्सपोर्ट किया गया
-
Power BI डैशबोर्ड को भेजा गया
-
FinOps ऑटोमेशन पाइपलाइन में एकीकृत
\
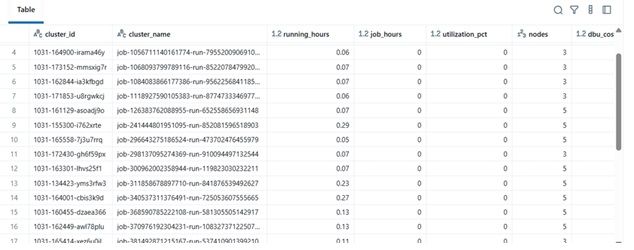
परिणाम उदाहरण
| cluster_name | running_hours | job_hours | utilization_pct | nodes | total_cost | |----|----|----|----|----|----| | etl-job-prod | 36.5 | 28.0 | 76.7% | 4 | $142.8 | | dev-debug | 12.0 | 1.2 | 10.0% | 2 | $18.4 | | nightly-adf | 48.0 | 45.0 | 93.7% | 6 | $260.4 |
\ 
\ \
-
वास्तविक-विश्व लाभ
इस विश्लेषक को लागू करके:
-
इंजीनियरिंग टीमें ऑडिट एक्सेस के बिना भी क्लस्टर लागत को ट्रैक कर सकती हैं।
-
मैनेजर को कम उपयोग वाले क्लस्टर में दृश्यता मिलती है।
-
DevOps स्वचालित रूप से कम उपयोग वाले क्लस्टर को समाप्त कर सकते हैं।
-
Finance आंतरिक मेट्रिक्स के साथ Databricks चालान को मान्य कर सकते हैं।
हमारे MSC प्रोजेक्ट में, हमने इसे अपने डेटा प्लेटफॉर्म ऑब्जर्वेबिलिटी स्टैक के हिस्से के रूप में उपयोग किया — REST API डेटा, ADF जॉब लॉग और लागत रुझानों को एक एकीकृत डैशबोर्ड में संयोजित करते हुए।
\


आपको यह भी पसंद आ सकता है

XRP Cup and Handle पैटर्न में ब्रेकआउट के लिए तैयार, टारगेट $1.70

ट्रंप ने पुस्तकालय और संग्रहालय की फंडिंग में भारी कटौती का प्रस्ताव रखा




