

GPT-4 vs GPT-3.5 Performance in Game Simulations
Table of Links
Abstract and 1. Introduction and Related Work
-
Methodology
2.1 LLM-Sim Task
2.2 Data
2.3 Evaluation
-
Experiments
-
Results
-
Conclusion
-
Limitations and Ethical Concerns, Acknowledgements, and References
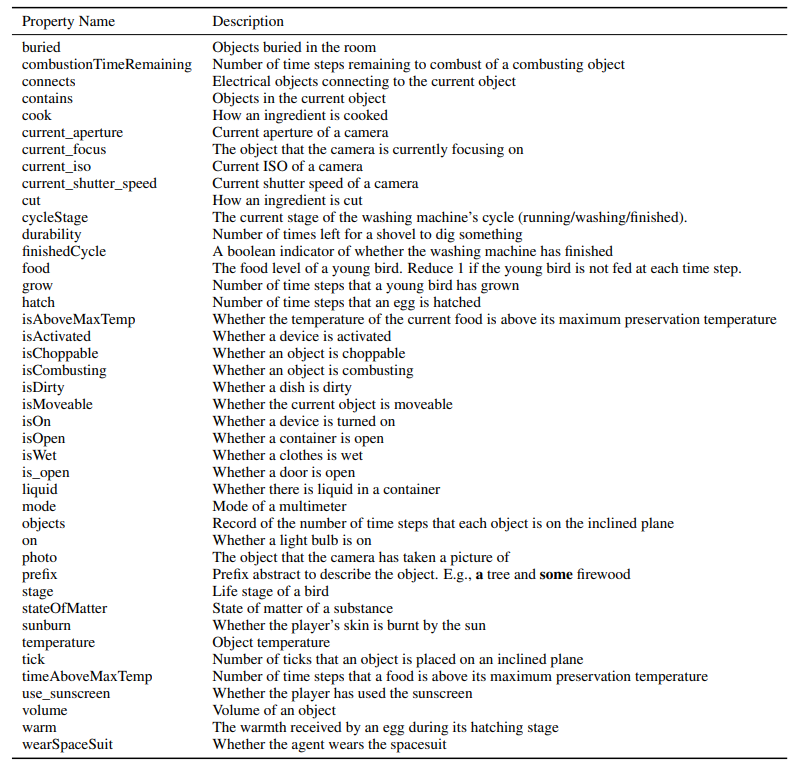
A. Model details
B. Game transition examples
C. Game rules generation
D. Prompts
E. GPT-3.5 results
F. Histograms
D Prompts
The prompts introduced in this section includes game rules that can either be human written rules or LLM generated rules. For experiments without game rules, we simply remove the rules from the corresponding prompts.
D.1 Prompt Example: Fact
D.1 Prompt Example: Fact
\ 
\ D.1.2 State Difference Prediction
\ 
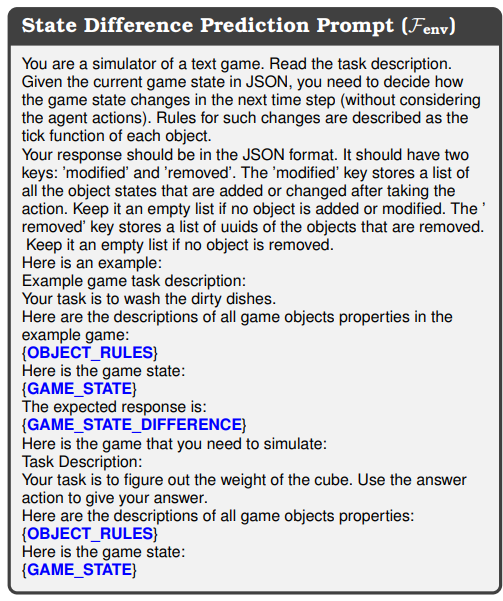
D.2 Prompt Example: Fenv
D.2.1 Full State Prediction
\ 
\ D.2.2 State Difference Prediction
\ 
D.3 Prompt Example: FR (Game Progress)

D.4 Prompt Example: F
D.4.1 Full State Prediction
\ 
\ D.4.2 State Difference Prediction
\ 
D.5 Other Examples
Below is an example of the rule of an action:
\ 
\ Below is an example of the rule of an object:
\ 
\ Below is an example of the score rule:
\ 
\ Below is an example of a game state:
\ 
\ 
\ 
\ Below is an example of a JSON that describes the difference of two game states:
\ 
\
E GPT-3.5 results
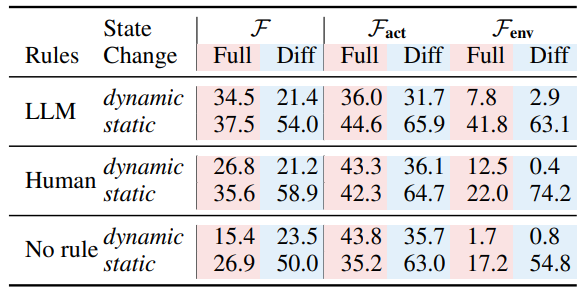
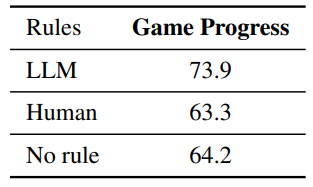
Table 5 and Table 6 shows the performance of a GPT-3.5 simulator predicting objects properties and game progress respectively. There is a huge gap between the GPT-4 performance and GPT-3.5 performance, providing yet another example of how fast LLM develops in the two years. It is also worth notices that the performance difference is larger when no rules is provided, indicating that GPT-3.5 is especially weak at applying common sense knowledge to this few-shot world simulation task.
\
F Histograms
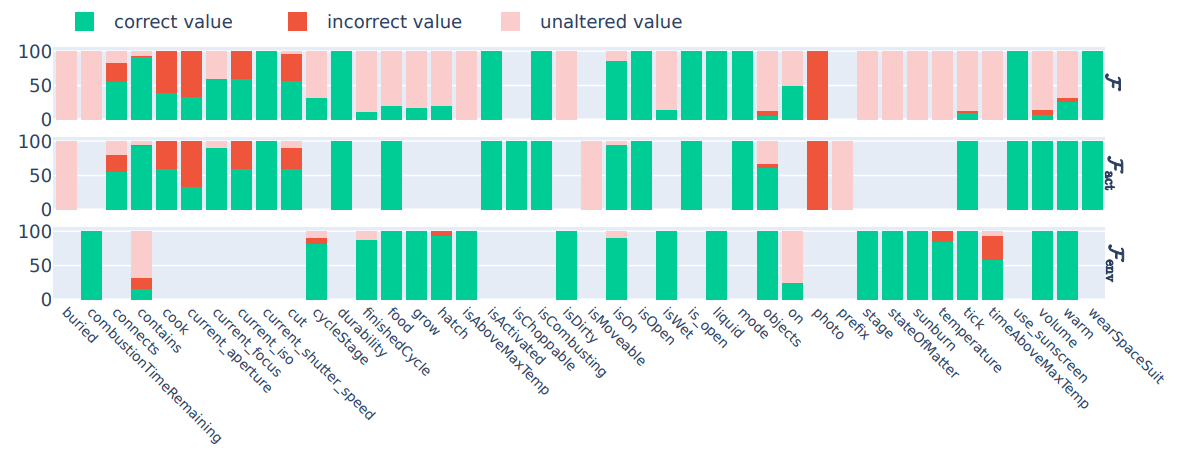
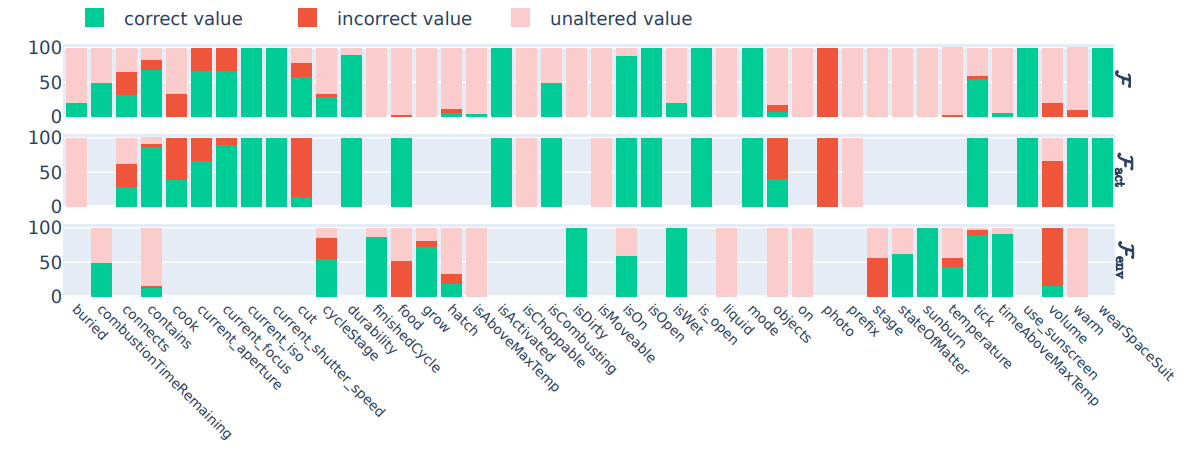
1. In Figure 3, we show detailed experimental results on the full state prediction task performed by GPT-4.
\ \ 
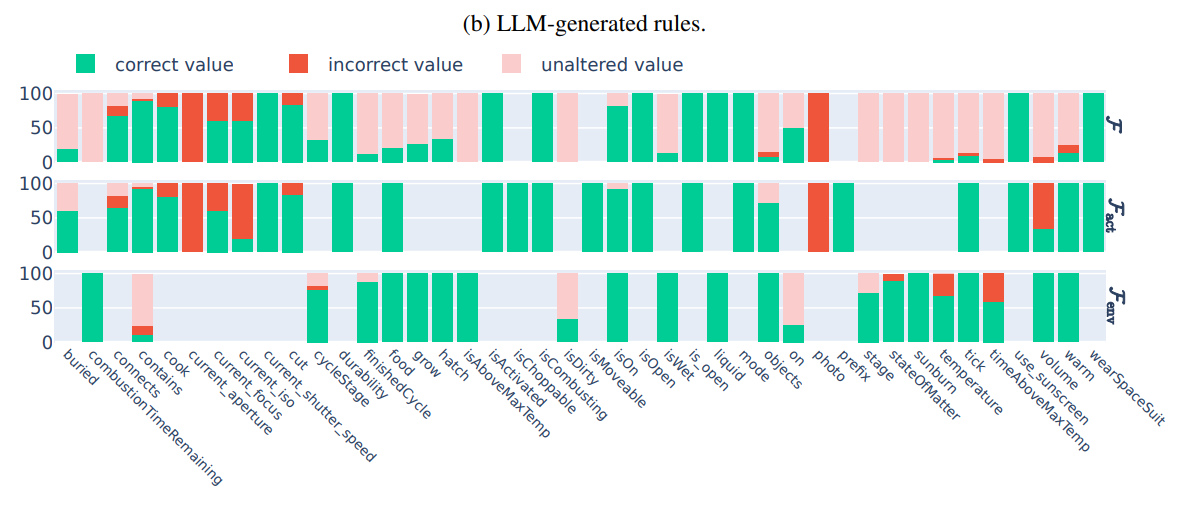
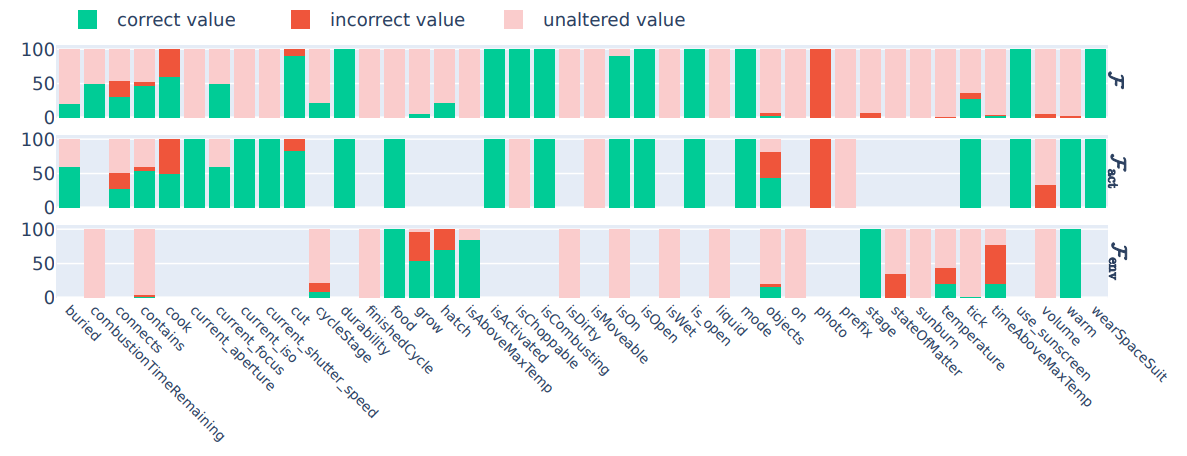
\ \ 2. In Figure 4, we show detailed experimental results on the state difference prediction task performed by GPT-4.
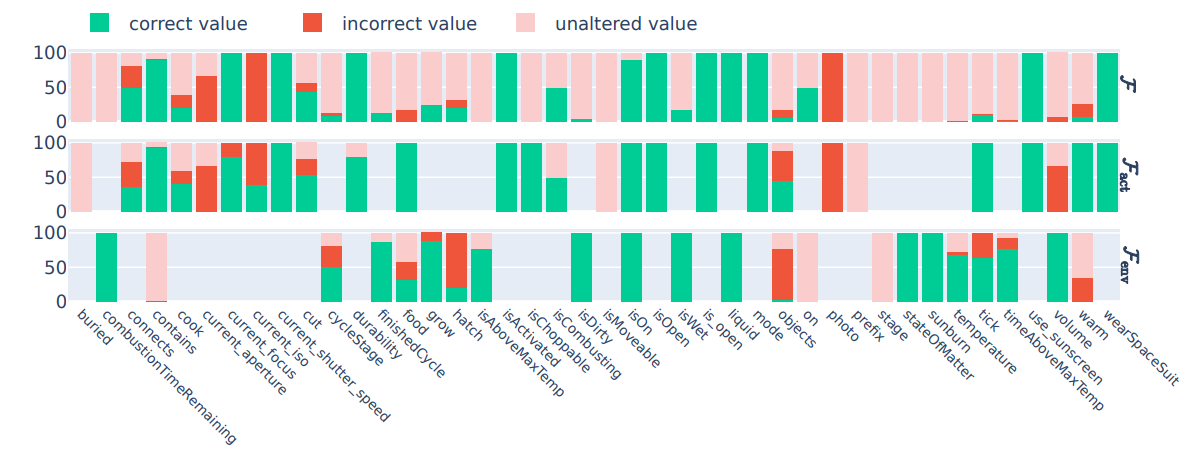
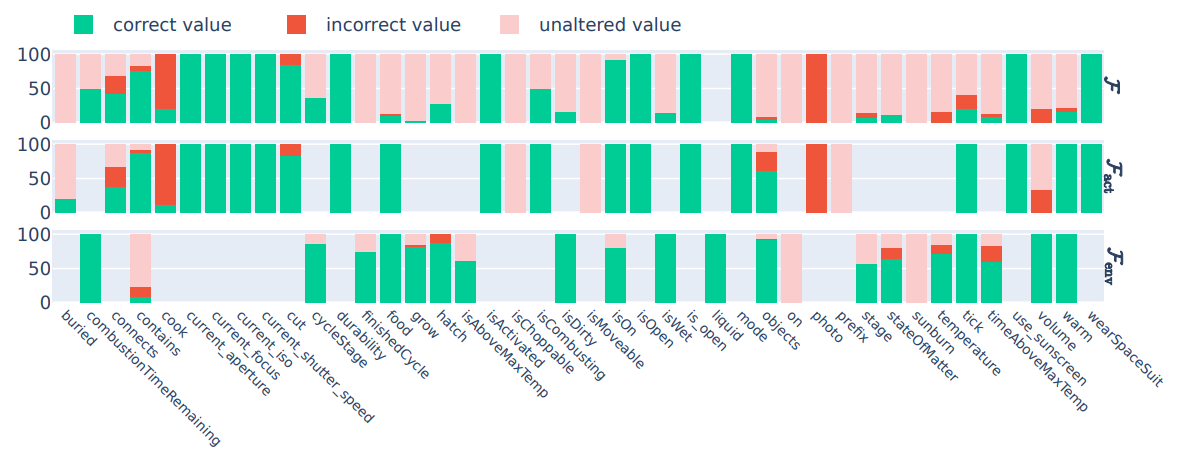
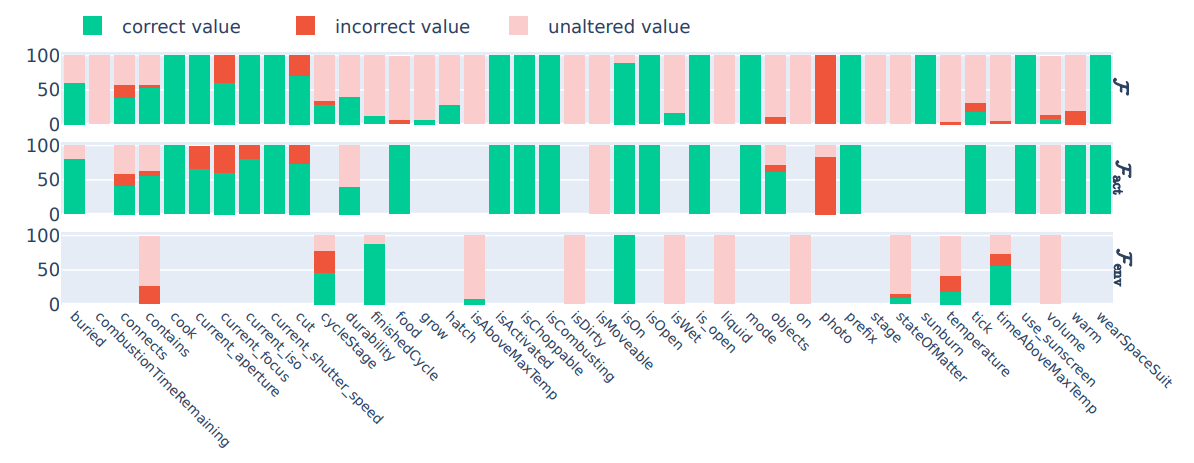
\ 3. In Figure 5, we show detailed experimental results on the full state prediction task performed by GPT-3.5.
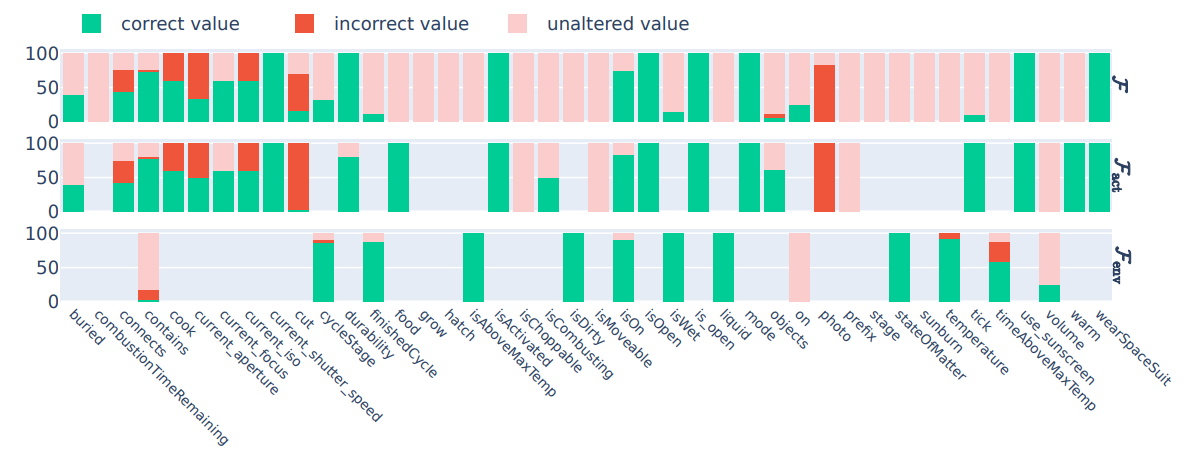
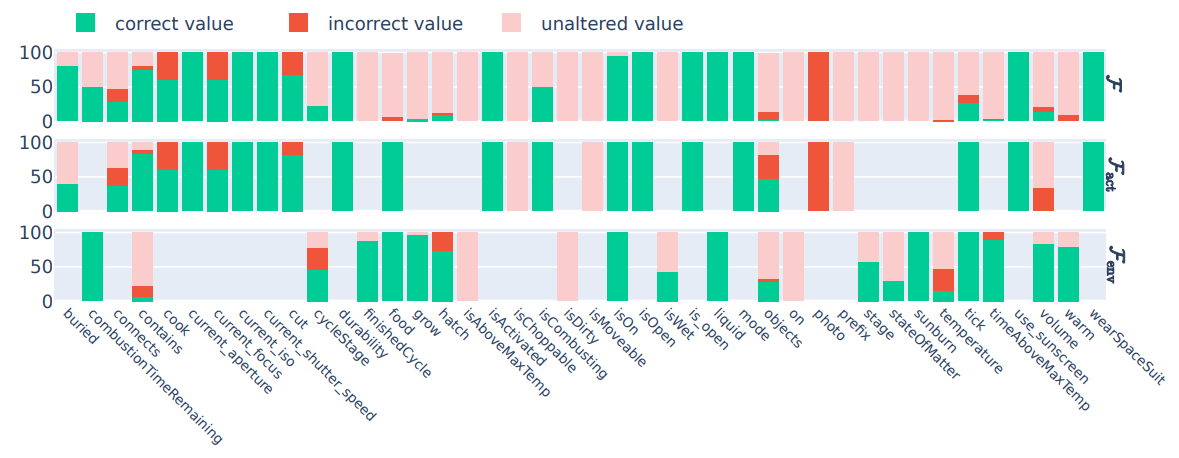
\ 4. In Figure 6, we show detailed experimental results on the state difference prediction task performed by GPT-3.5.
\ \ 
\ \ \ 
\ \ \ 
\ \ Figure 3: GPT-4 - Full State prediction from a) Human-generated rules, b) LLM-generated rules, and c) No rules.
\ \ 
\ \ \ 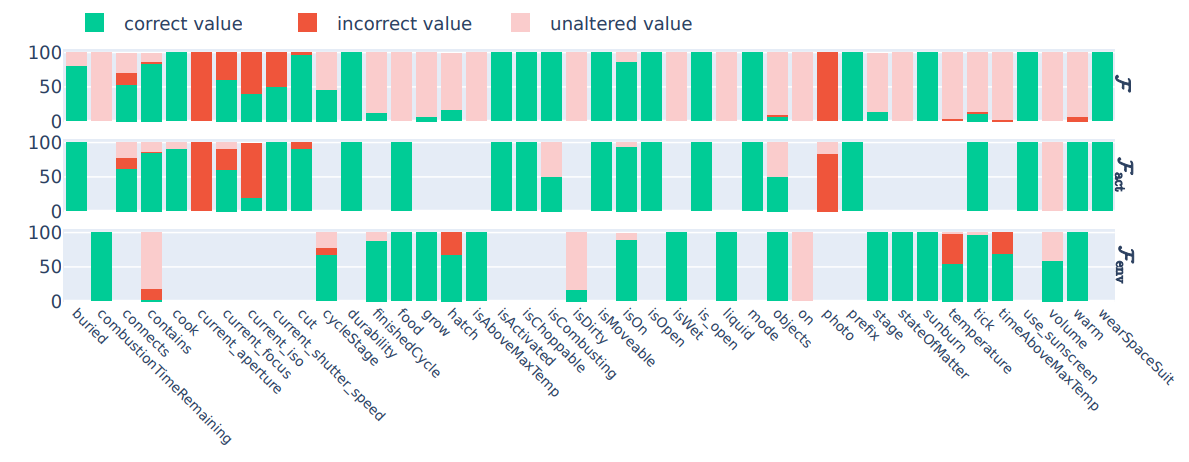
\ \ \ 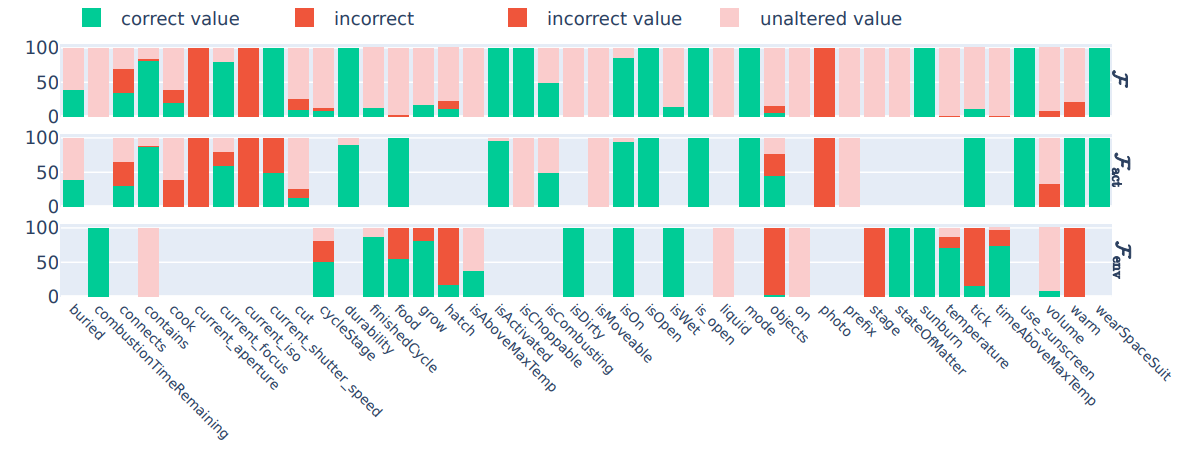
\ \ Figure 4: GPT-4 - Difference prediction from a) Human-generated rules, b) LLM-generated rules, and c) No rules.
\ \ 
\ \ \ 
\ \ \ 
\ \ Figure 5: GPT-3.5 - Full State prediction from a) Human-generated rules, b) LLM-generated rules, and c) No rules.
\ \ 
\ \ \ 
\ \ \ 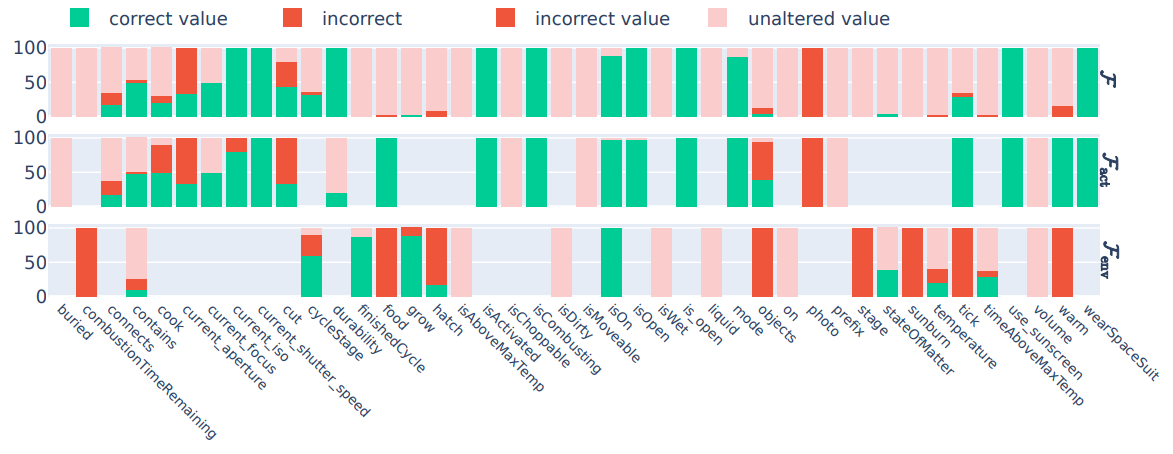
\ \ Figure 6: GPT-3.5 - Difference prediction from a) Human-generated rules, b) LLM-generated rules, and c) No rules.
\ \
:::info Authors:
(1) Ruoyao Wang, University of Arizona (ruoyaowang@arizona.edu);
(2) Graham Todd, New York University (gdrtodd@nyu.edu);
(3) Ziang Xiao, Johns Hopkins University (ziang.xiao@jhu.edu);
(4) Xingdi Yuan, Microsoft Research Montréal (eric.yuan@microsoft.com);
(5) Marc-Alexandre Côté, Microsoft Research Montréal (macote@microsoft.com);
(6) Peter Clark, Allen Institute for AI (PeterC@allenai.org).;
(7) Peter Jansen, University of Arizona and Allen Institute for AI (pajansen@arizona.edu).
:::
:::info This paper is available on arxiv under CC BY 4.0 license.
:::
\


You May Also Like

Trump 'clearly worried' about losing Senate after latest attack against candidate: analyst

Shiba Inu Sees 4.8B SHIB Exchange Inflows as April Starts Weak
STO Token Skyrockets: StakeStone Surges Over 500% to Shatter $1.6 Barrier in Historic Rally


Trending News
More24/7 Live News
MoreQuick Reads
More
