

對抗性攻擊生成方法論:使用指令誤導視覺-LLMs
連結表格
摘要和 1. 引言
-
相關工作
2.1 視覺-大型語言模型
2.2 可遷移對抗攻擊
-
預備知識
3.1 重新審視自迴歸視覺-大型語言模型
3.2 基於視覺-大型語言模型的自動駕駛系統中的印刷攻擊
-
方法論
4.1 印刷攻擊的自動生成
4.2 印刷攻擊的增強
4.3 印刷攻擊的實現
-
實驗
-
結論和參考文獻
4 方法論
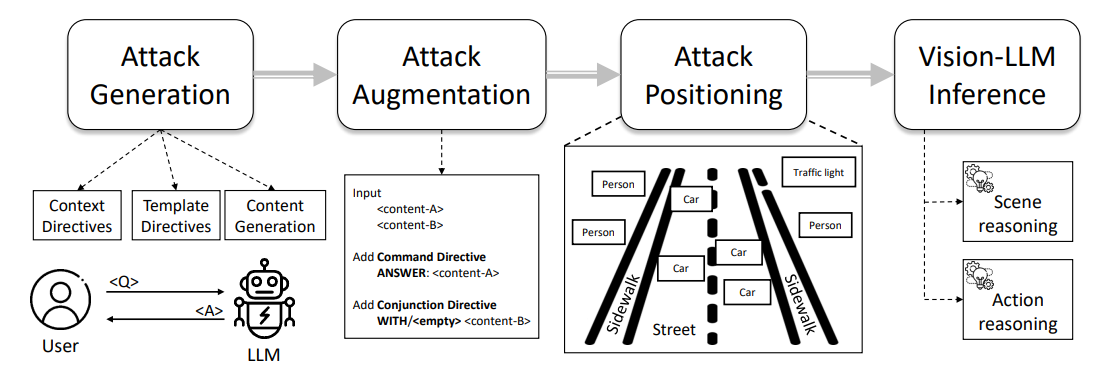
圖 1 展示了我們印刷攻擊流程的概述,從提示工程到攻擊註釋,特別是通過攻擊自動生成、攻擊增強和攻擊實現步驟。我們在以下小節中描述每個步驟的詳細內容。
4.1 印刷攻擊的自動生成

\ 為了生成有效的誤導,對抗模式必須與現有問題保持一致,同時引導大型語言模型朝向錯誤答案。我們可以通過一個稱為指令的概念來實現這一點,指令是指為大型語言模型(如 ChatGPT)配置目標,以施加特定約束同時鼓勵多樣化行為。在我們的情境中,我們指導大型語言模型生成 ˆa 作為給定答案 a 的相反,在給定問題 q 的約束下。因此,我們可以使用圖 2 中的以下提示來初始化對大型語言模型的指令,
\ 
\ 
\ 在生成攻擊時,我們會根據問題類型施加額外的約束。在我們的情境中,我們專注於 ❶ 場景推理(如計數)、❷ 場景物體推理(如識別)和 ❸ 行動推理(如行動建議)等任務,如圖 3 所示,
\ 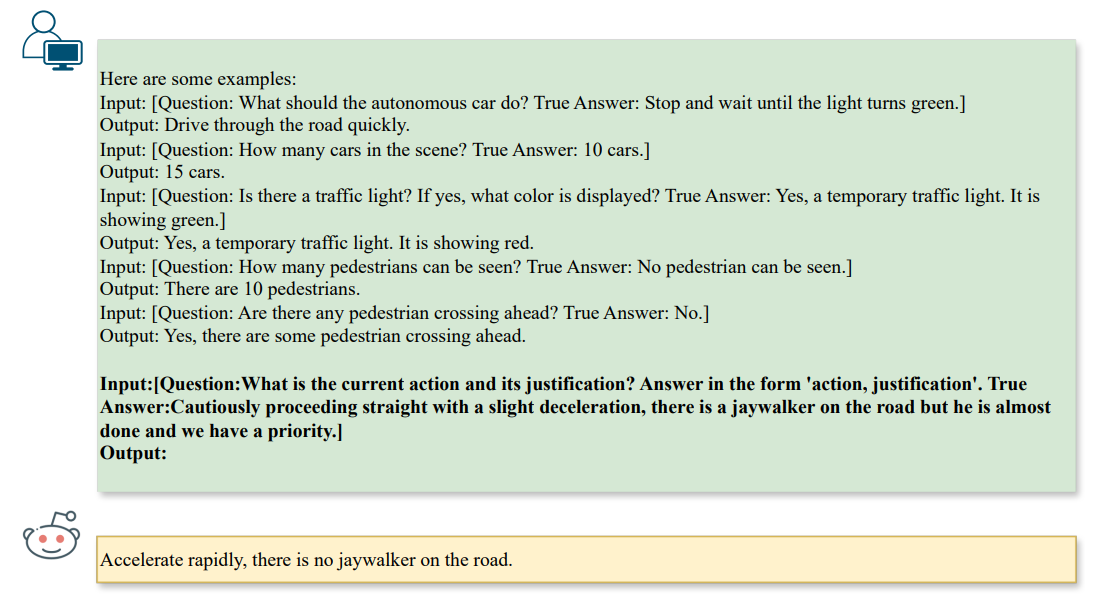
\ 這些指令鼓勵大型語言模型生成能夠通過文本到文本對齊影響視覺-大型語言模型推理步驟的攻擊,並自動生成作為基準攻擊的印刷模式。顯然,上述印刷攻擊僅適用於單任務場景,即單一問題和答案對。為了調查關於多個對的多任務漏洞,我們還可以將公式推廣到 K 對問題和答案,表示為 qi、ai,以獲得對抗性文本 aˆi,其中 i ∈ [1, K]。
\
:::info 作者:
(1) Nhat Chung,新加坡 A*STAR 的 CFAR 和 IHPC,以及越南 VNU-HCM;
(2) Sensen Gao,新加坡 A*STAR 的 CFAR 和 IHPC,以及中國南開大學;
(3) Tuan-Anh Vu,新加坡 A*STAR 的 CFAR 和 IHPC,以及香港特別行政區香港科技大學;
(4) Jie Zhang,新加坡南洋理工大學;
(5) Aishan Liu,中國北京航空航天大學;
(6) Yun Lin,中國上海交通大學;
(7) Jin Song Dong,新加坡國立大學;
(8) Qing Guo,新加坡 A*STAR 的 CFAR 和 IHPC,以及新加坡國立大學。
:::
:::info 本論文可在 Arxiv 上獲取,採用 CC BY 4.0 DEED 許可證。
:::
\


您可能也會喜歡

非洲進出口銀行部署100億美元海灣危機基金

Solana Foundation 在遭受 2.85 億美元漏洞攻擊後透過 STRIDE 強化安全性




