

That Time We Found Gender Bias Hidden in a Podcast Recommendation System

Table of links
Abstract
1 Introduction
2 Related Work
2.1 Fairness and Bias in Recommendations
2.2 Quantifying Gender Associations in Natural Language Processing Representations
3 Problem Statement
4 Methodology
4.1 Scope
4.3 Flag
5 Case Study
5.1 Scope
5.2 Implementation
5.3 Flag
6 Results
6.1 Latent Space Visualizations
6.2 Bias Directions
6.3 Bias Amplification Metrics
6.4 Classification Scenarios
7 Discussion
8 Limitations & Future Work
9 Conclusion and References
\
5 Case Study
In this section, we present an industry case study of how we leveraged our framework to analyze attribute association bias in a podcast LFR system. We discuss how we implemented our framework to scope the attribute for bias measurement, identify and implement appropriate measurement methods, and flag potentially embedded bias in our LFR outputs.
\ 5.1 Scope
5.1.1 Deciding On An Attribute.
Our case study evaluates user gender attribute association bias in item embeddings stemming from LFR models. This disaggregated evaluation targets understanding how recommendations of specific pieces or types of content may vary according to a user’s gender. Beyond the scope of this work, user gender bias has been largely unexplored concerning recommendation algorithms due to the difficulty in obtaining the user’s gender for analysis. As mentioned in §2, gender bias has been primarily explored relating to creator or provider gender in media recommendation – e.g., distributional fairness of artist gender in music recommendations [26, 41] and distribution of author gender in book recommendations [25]. Outside of academic settings, gender bias has also been studied in several industry recommender systems. For example, the audit by Geyik et al. [29] examining ranking on LinkedIn is an example of evaluating the rank fairness according to gender in a recommendation system in production. Chen et al. [16] evaluated how gender affects rank performance on job sites, such as Indeed and Monster. Dash et al. [19] conducted a large scale audit on ranking bias in relation to gender for Amazon recommendations. These industry case studies showcase how gender bias previously studied in more qualitative settings can be quantified and observed in recommendation settings.
The influence of gender on media preferences is a wellresearched phenomenon outside of recommendation systems. Wühr et al. [60] studied gendered genre preference in movies, finding that women preferred romance and drama while men preferred genres including science fiction, action, and adventure. Gendered genre preferences have also been shown for digital games; Lange et al. [32] conducted a study on 484 female and male participants comparing actual and stereotyped gender preferences in digital game genres. Gendered genre preferences have also been found in studies concerning the motivation for reading books and music listening [10, 42, 55]. Our case study contributes to both gender bias industry research and academic observations of gendered media preferences, specifically gender bias in podcast recommendations.
Our case study provides a quantitative deep dive into biased listening behavior previously observed in qualitative academic studies. These studies provided guidance for grouping our entity vectors to implement our analysis methods; we decided that exploring user gender attribute association bias would provide a good case study for experimenting with our framework and contributing novel insight into this area of research. For example, Boling and Hull [12] found listeners of true crime podcasts were predominately female and showed three specific motivations. Craig et al. [18] found that motivations for podcast use in young adults did not significantly change across gender but across genres, signaling a potential change in gender and genre combined. Soto-Vásquez et al. [52] presented results showing that various demographic parameters, including gender, drove podcast interests in Latina/o/x young people. However, these stereotypes have yet to be researched quantitatively via bias evaluation in the context of recommendation systems. In this paper, we continue investigating the relationship between gender and genre by analyzing and quantifying potential user gender bias captured in the trained latent space representation from a recommendation model.
\ 5.1.2 Defining Entity Sets. After deciding to target user gender attribute association bias, we needed to determine how to group our entities for analysis. We can group male and female users into our attribute-defining entity sets to target user gender. Nevertheless, we must also determine how to frame our entity sets to test for user gender bias given the variety of possible stereotypes associated with user gender. For example, one could frame the analysis to understand if there is user gender attribute association bias regarding creator gender. An Edison report focusing on podcast listening behavior of women found that women would listen to more podcasts if there were more female hosts within the podcast space [33]. Another industry study by AT&T found that men were likelier to listen to podcasts hosted by men [1].
\ Instead of framing our analysis that way, we chose to target how user gender may become associated with specific genres of podcasts. We looked to past research on podcast genre listening behaviors by gender to determine which genres we should define as test entity groups. In particular, Boling and Hull [12] noted that true crime podcast listeners are more likely to be female than male, and true crime is one of the most popular genres in female listening [33]. In contrast, sports podcasts have been found to have a primarily male listenership [31]. When observing proprietary data concerning gender share in listenership, we confirmed that these two genres were significantly skewed towards women for true crime and towards men for sports. Given these findings, we explored gender attribute association bias for podcasts labeled as true crime or sports. Our podcast vectors were labeled by predetermined podcast genres. These genre labels were defined via self-selection from podcast hosts and behind-the-scenes cataloging of podcasts. Because a podcast can be classified under multiple genres, we required podcasts labeled as true crime not to be labeled as sports and vice versa.
\ 5.1.3 Determining Where To Evaluate. Recommender systems in industry settings are commonly designed as hybrid recommendation systems consisting of multiple components to create final predictions [14]. Often these consist of candidate generation and ranking components [6]. In many settings, the candidate generation component leverages a LFR algorithm (such as DNN or collaborative filtering) to create user and item embeddings; these embeddings are used by downstream components to further refine the candidate pool via k-nearest neighbors or providing final rankings with rank-specific algorithms [6]. Within this type of recommendation system, we hypothesize that attribute association bias can be introduced via LFR components. We test this by measuring attribute association bias from a LFR algorithm and then observing how attribute association bias can be captured via item vectors with classification models. We plan for future iterations of this framework to provide ways to quantify attribute association bias in ranked lists. We evaluate user gender attribute association bias regarding podcast genre by implementing our framework on an industry hybrid recommendation system.
\ We decided to evaluate the first component of the system as the earliest point in which this type of bias could be introduced into final recommendations. This component is an industry production-level candidate generation model for podcast recommendation; it uses an LFR algorithm to create pools of podcast vectors by user to be ranked for final recommendation lists. More specifically, candidates are generated via a deep neural network (DNN) recommendation model, a setup commonly used in industry systems [17, 43]. It mimics matrix factorization collaborative filtering via a DNN and is trained with candidate sampling and importance weighting to account for potential popularity bias. Model inputs include user features, podcast ids, and binary labels representing positive or negative implicit feedback. Final user and podcast (or item) representation embedding vectors are collected as outputs from the model.
\ We trained the model with and without using user gender as a feature to understand the counterfactual effects and potential for implicit bias when trained without explicit use of the sensitive feature. This also enabled us to explore use of our framework for creating baselines for mitigation methods, such as removing sensitive attributes from a model. All analysis and training were conducted offline due to the sensitivity of mitigating user gender bias in an online industry system.
\ 5.1.4 Scoping Evaluation Data. We created our evaluation data set by randomly sampling 9,500 female and male users to create a final set of 19,000 users. Our podcast vector data set comprised 31,181 English podcasts from the DNN recommendation model. We restricted our analysis of recommendations to users registered in the United States and podcasts created by English speakers. We chose this subset of data to minimize the possibility of location and language confounds, which could potentially affect gender bias measurements due to differences in cultural norms. In the future, it would be interesting to research how gender stereotypes are found as algorithmic bias differently in recommendations concerning the location and language of the users and served content.
\ 5.2 Implementation
This section describes implementation of our proposed techniques for this case study. We defined our attribute-defining entity sets, 𝐹 and 𝑀, as users labeled as female or male. Our test entity sets, 𝑆 and 𝑇𝐶, were defined as podcasts categorized as sports and true crime respectively. Podcasts in entity set 𝑆 are mutually exclusive with those in 𝑇𝐶. Based on our scoped evaluation goals, we chose these groupings to observe the effects of user gender attribute association bias on genres of podcast embeddings. In order to test the ability of our methods to flag changes in bias, we implemented a simple mitigation of removing user gender as a feature during model training, resulting in an evaluation of embeddings trained with and without user gender.
\ 5.2.1 Latent Space Visualizations. We apply PCA for dimensionality reduction to visualize embeddings of users and podcasts trained with and without gender. We used the
\ 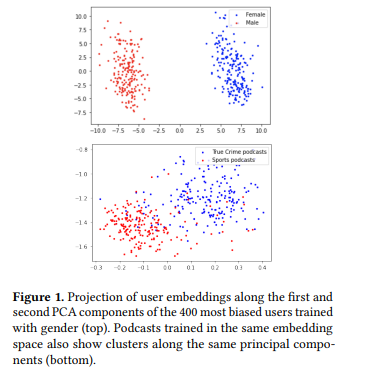
200 male and 200 female users with the greatest cosine similarity with our attribute bias vector. We then projected the podcast embeddings onto the vector space learned by PCA applied to the 400 most biased users to observe clustering along the same axis. Since the first principal component was highly correlated with our “bias” vector, we can consider it a proxy for gendered meaning in our podcasts. Therefore, for our feature vectors to have a degree of variation explained by this same vector demonstrates the latent representation of gender in feature vectors.
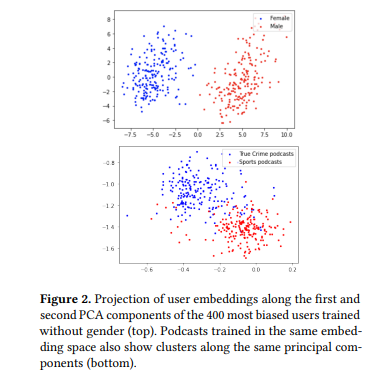
We replicated this process with our user and podcast embeddings trained without a gender feature. If removing the gender feature removed gendered meaning from the user embeddings, we would expect the same set of 400 “biased” users not to be segregated along the first principal component. We used the same set of 400 users and retrained PCA on the “without gender” embeddings.
\ 5.2.2 Bias Directions. We used gender-labeled user vectors for each defined approach (centroid, SVC, and PCA) to create the bias directions. These directions were then used to evaluate possible attribute association bias of the test podcast entity sets.
Centroid Difference. For centroid difference, we simply subtracted the centroid vector of set 𝐹 from that of set 𝑀.
SVC. We experimented with three ways to create our SVC model direction based on the entities included during training. The first direction did not consider possible attribute bias of the entities by training the SVC model on a random
\ 
sample of 6,000 male and 6,000 female users. The final attribute layer of this model was the final user gender bias direction. We evaluated the training accuracy to determine if the model successfully captured significant gender meaning. We chose to implement multiple levels of perceived bias to allow us to analyze how results are affected by the types of entities leveraged during training. For the following two directions, we defined our entity sets based on their expected level of attribute bias, inspired by Gonen and Goldberg [30] where they only leveraged word vectors heavily associated with societal gendered stereotypes to create directions. We used the centroid difference direction for identifying users with the most “biased” representations, meaning they had the highest cosine similarity with the centroid bias vector. We then trained the SVC model on the 200 and 2500 most “biased” male and female user vectors (400 and 5000 user vectors total); we refer to these as CSVC-1 and CSV-2 respectively.
\ PCA. When implementing the PCA direction method, we needed a method to create user embedding pairings to capture the user gender attribute since our training data did not explicitly specify user pairings based on user gender. We did so by randomly sampling pairs between male and female user vectors. We did not account for the centroid bias of the users during sampling. The final gender direction vector was the first eigenvector of the resulting principal components of these random user pairings.
\ 5.2.3 Bias Evaluation Metrics. In order to implement our entity attribute association metrics, we defined our two attribute-defining groups and test entity groups as described above. Implementing these metrics represented the association between female users and stereotypically “female” podcasts and vice versa with male users and podcasts. We used the gender bias direction vectors described above as our relation vectors for calculating R-RIPA.
\ 5.2.4 Classification Scenarios. We experimented with three classification training scenarios to explore how user gender can affect recommendations differently. We chose to explore how models trained on user vectors in entity sets 𝐹 and 𝑀 to predict user gender can be repurposed to predict other classification scenarios leveraging only podcast vectors. By doing so, we can evaluate if similar patterns of user gender bias are embedded into item vectors as in user vectors. In our first classification scenario, we change the classification target variable to predict if most of a podcast’s listeners are female or male. We explore the model’s performance by analyzing how predicted labels change according to the percentage split between genders. The podcast vectors are used as input into the original models trained to predict user gender from user vectors, with comparison between the gender label output and actual listening splits of the podcast. This scenario is modeled to observe if podcast vectors can relay or reinforce gendered listening behavior.
\ Second, we use a binary classification model to predict if a user is female or male based on their past podcast listening history. The training data consisted of the centroid of top-3 podcast vectors from each user’s listening history. The target variable was the user’s gender. We formulated our classification model to observe the potential for podcast vectors to relay user gender bias in downstream recommendation system components. Additionally, in many industry systems, trained recommendation representation embeddings are leveraged in other models to represent content as a feature. If podcast vectors can successfully predict a user’s gender, it could signal that these vectors may inadvertently amplify or introduce gender bias into a downstream machine learning model. Finally, we assess bias at the genre level to determine if genre previously flagged by qualitative studies as experiencing high rates of gendered preference, like true crime and sports podcasts, are more or less affected by the gender bias direction [18, 31]. We train a binary classification model to predict the “gender” of the podcasts in the test entity sets 𝑆 and 𝑇𝐶.
\ 5.3 Flag
We apply the significance tests proposed in the methodology section to validate the implemented bias directions and metrics. This testing step included three tests of significance for the bias directions and permutation testing to determine the significance of changes in our EAA metric results.
For the classification scenarios, we tracked precision, recall, and F1-score across true crime and sports podcasts. We set true labels for podcasts based on their associated stereotype, so “true” labels for true crime and sports were “female” and “male” respectively. We used a chi-squared test to determine if results were significantly different when trained with or without user gender as an explicit feature. We compared results between the genre groups with a Mann-Whitney test between the distribution of “correctly” predicted podcasts. When evaluating the gendered listening majority percentage, we observed these metrics at different deciles of gender listenership; this allowed us to provide insight into how attribute association bias may change for item embeddings with higher or lower rates of gendered listening. One can test for significance between deciles with a chi-square test comparing results between two deciles. However, for our analysis, we leveraged this analysis as a way to break down results and were less concerned with the significance between deciles. Understanding differences between these groups would be necessary for more targeted mitigation methods.
:::info Authors:
- Lex Beattie
- Isabel Corpus
- Lucy H. Lin
- Praveen Ravichandran
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
\


You May Also Like

AI predicts XRP price for April 30, 2026

Lovable AI’s Astonishing Rise: Anton Osika Reveals Startup Secrets at Bitcoin World Disrupt 2025




