

See, Track, Describe: How OW‑VISCap Lets AI Tell the Story Behind Every Frame
:::info Authors:
(1) Anwesa Choudhuri, University of Illinois at Urbana-Champaign (anwesac2@illinois.edu);
(2) Girish Chowdhary, University of Illinois at Urbana-Champaign (girishc@illinois.edu);
(3) Alexander G. Schwing, University of Illinois at Urbana-Champaign (aschwing@illinois.edu).
:::
Table of Links
Abstract and 1. Introduction
-
Related Work
2.1 Open-world Video Instance Segmentation
2.2 Dense Video Object Captioning and 2.3 Contrastive Loss for Object Queries
2.4 Generalized Video Understanding and 2.5 Closed-World Video Instance Segmentation
-
Approach
3.1 Overview
3.2 Open-World Object Queries
3.3 Captioning Head
3.4 Inter-Query Contrastive Loss and 3.5 Training
-
Experiments and 4.1 Datasets and Evaluation Metrics
4.2 Main Results
4.3 Ablation Studies and 4.4 Qualitative Results
-
Conclusion, Acknowledgements, and References
\ Supplementary Material
A. Additional Analysis
B. Implementation Details
C. Limitations
\ Abstract. Open-world video instance segmentation is an important video understanding task. Yet most methods either operate in a closedworld setting, require an additional user-input, or use classic region-based proposals to identify never before seen objects. Further, these methods only assign a one-word label to detected objects, and don’t generate rich object-centric descriptions. They also often suffer from highly overlapping predictions. To address these issues, we propose Open-World Video Instance Segmentation and Captioning (OW-VISCap), an approach to jointly segment, track, and caption previously seen or unseen objects in a video. For this, we introduce open-world object queries to discover never before seen objects without additional user-input. We generate rich and descriptive object-centric captions for each detected object via a masked attention augmented LLM input. We introduce an inter-query contrastive loss to ensure that the object queries differ from one another. Our generalized approach matches or surpasses state-of-the-art on three tasks: open-world video instance segmentation on the BURST dataset, dense video object captioning on the VidSTG dataset, and closed-world video instance segmentation on the OVIS dataset.
\
1 Introduction
Open-world video instance segmentation (OW-VIS) involves detecting, segmenting and tracking previously seen or unseen objects in a video. This task is challenging because the objects are often never seen during training, are occasionally partly or entirely occluded, the appearance and position of these objects changes over time, and because the objects may leave the scene only to re-appear at a later time. Addressing these challenges to obtain an accurate method for OWVIS that works online is crucial in fields like autonomous systems, and augmented as well as virtual reality, among others.
\ Some recent methods based on abstract object queries perform remarkably well for closed-world video instance segmentation [7, 13, 18, 50]. These works assume a fixed set of object categories during training and evaluation. However, it is unrealistic to assume that all object categories are seen during training. For example, in Fig. 1, the trailer truck (top row) highlighted in yellow, and the lawn mower (bottom row) highlighted in green, are never seen before during training.
\ 
\ For this reason, open-world video instance segmentation (OW-VIS) has been proposed [2,10,27,28,39,44]. Current works on OW-VIS suffer from the following three main issues. Firstly, they often require a prompt, i.e., additional input from the user, ground-truth or another network. The prompts can be in the form of points, bounding boxes or text. These methods only work when the additional inputs are available, making them less practical in the real-world. Prompt-less OW-VIS methods [2, 10, 27, 28, 39, 44] sometimes rely on classic region-based object proposals [2,27,28,44], or only operate on one kind of object query for both the open- and the closed-world [10, 39], which may result in sub-optimal results (shown later in Tab. 4). Secondly, all methods on video instance segmentation, closed- or open-world, assign a one-word label to the detected objects. However, a one word label is often not sufficient to describe an object. The ability to generate rich object-centric descriptions is important, especially in the open-world setting. DVOC-DS [58] jointly addresses the task of closed-world object detection and object-centric captioning in videos. However, it is not clear how DVOC-DS [58] can be extended to an open-world setting. Besides, the features from only the individual object trajectories are used for object-centric captioning in DVOCDS [58], so the overall context from the entire video frames may be lost in this method. DVOC-DS [58] also struggles with very long videos, and cannot caption multiple action segments within a single object trajectory because the method produces a single caption for the entire object trajectory. Thirdly, some of the aforementioned works [7, 8, 13, 18] suffer from multiple similar object queries resulting in repetitive predictions. Non-maximum suppression, or other postprocessing techniques may be necessary to suppress the repetitions and highly overlapping false positives.
\ We address the three aforementioned issues through our Open-World Video Instance Segmentation and Captioning (OW-VISCap) approach: it simultaneously detects, segments and generates object-centric captions for objects in a video. Fig. 1 shows two examples in which our method successfully detects, segments and captions both closed- and open-world objects.
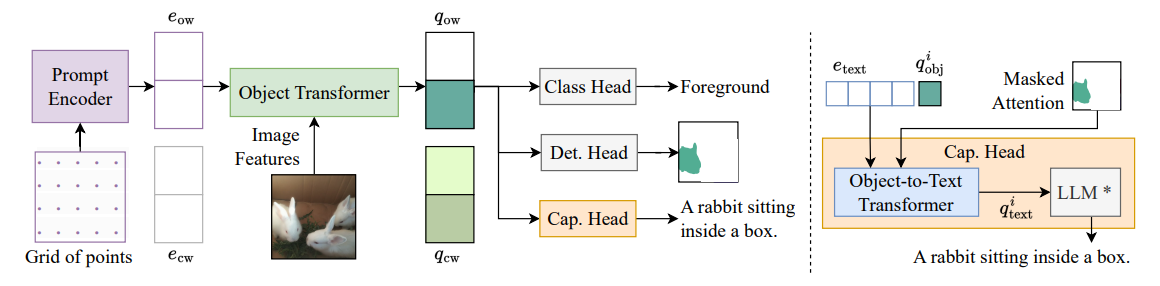
\ To address the first issue, our OW-VISCap combines the advantages of both prompt-based and prompt-less methods. We introduce open-world object queries, in addition to closed-world object queries used in prior work [8]. This encourages discovery of never before seen open-world objects without compromising the closed-world performance much. Notably, we do not require additional prompts from the ground truth or separate networks. Instead, we use equally spaced points distributed across the video frames as prompts and encode them to form open-world object queries, which enables discovery of new objects. The equally spaced points incorporate information from different spatial regions of the given video-frames. We also introduce a specifically tailored open-world loss to train the open-world object queries to discover new objects.
\ To address the second issue, OW-VISCap includes a captioning head to produce an object-centric caption for each object query, both open- and closedworld. We use masked cross attention in an object-to-text transformer in the captioning head to generate object-centric text queries, that are then used by a frozen large language model (LLM) to produce an object-centric caption. Note, masked attention has been used for closed-world object segmentation [7,8]. However, to our best knowledge it has not been used for object captioning before. The masked cross attention helps focus on the local object features, whereas the self attention in the object-to-text transformer incorporates overall context by looking at the video-frame features. Moreover, unlike DVOC-DS [58], we are able to handle long videos and multiple action segments within a single object trajectory because we process short video clips sequentially and combine the clips using CAROQ [13].
\ To address the third issue, we introduce an inter-query contrastive loss for both open- and closed-world object queries. It encourages the object queries to differ from one another. This prevents repetitive predictions and encourages novel object discovery in the open-world. Note that this contrastive loss also helps in closed-world video instance segmentation by automatically encouraging non-maximum suppression, and by removing highly overlapping false positive predictions.
\ To demonstrate the efficacy of our OW-VISCap on open-world video instance segmentation and captioning, we evaluate this approach on three diverse and challenging tasks: open-world video instance segmentation (OW-VIS), dense video object captioning (Dense VOC), and closed-world video instance segmentation (VIS). We achieve a performance improvement of ∼ 6% on the previously unseen (uncommon) categories in the BURST [2] dataset for OW-VIS, and a ∼ 7% improvement on the captioning accuracy for detected objects on the VidSTG [57] dataset for the Dense VOC task, while performing similar to the state-of-the-art on the closed-world VIS task on the OVIS data (our AP score is 25.4 as compared to a score of 25.8 for a recent VIS SOTA, CAROQ [13]).
\ 
\
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
\


You May Also Like

Top Crypto to Watch Right Now? Experts Highlight This Altcoin Under $1

Kalshi, Hyperliquid Defy Dutch Ban as Polymarket Exit Raises Stakes




