

Related Work on Closed‑Set 3D Segmentation, Open‑Vocabulary 2D Recognition, and SAM/CLIP‑Based 3D Ap
Table of Links
Abstract and 1 Introduction
- Related works
- Preliminaries
- Method: Open-YOLO 3D
- Experiments
- Conclusion and References
A. Appendix
2 Related works
Closed-vocabulary 3D segmentation: The 3D instance segmentation task aims at predicting masks for individual objects in a 3D scene, along with a class label belonging to the set of known classes. Some methods use a grouping-based approach in a bottom-up manner, by learning embeddings in the latent space to facilitate clustering of object points [4, 14, 15, 21, 26, 29, 46, 54]. Conversely, proposalbased methods adopt a top-down strategy, initially detecting 3D bounding boxes and then segmenting the object region within each box [10, 17, 31, 49, 52]. Notably, inspired by advancements in 2D works [5, 6], transformer designs [43] have been recently applied to 3D instance segmentation tasks [39, 41, 24, 1, 20]. Mask3D [39] introduces the first hybrid architecture that combines Convolutional Neural Networks (CNN) and transformers for this task. It uses a 3D CNN backbone to extract per-point features and a transformer-based instance mask decoder to refine a set of queries. Building on Mask3D, the authors of [1] show that using explicit spatial and semantic supervision at the level of the 3D backbone further improves the instance segmentation results. Oneformer3D [24] follows a similar architecture and introduces learnable kernels in the transformer decoder for a unified semantic, instance, and panoptic segmentation. ODIN [20] proposes an architecture that uses 2D-3D fusion to generate the masks and class labels. Other methods introduce weakly-supervised alternatives to dense annotation approaches, aiming to reduce the annotation cost associated with 3D data [8, 18, 47]. While these methodologies strive to enhance the quality of 3D instance segmentation, they typically rely on a predefined set of semantic labels. In contrast, our proposed approach aims at segmenting objects with both known and unknown class labels.
\ Open-vocabulary 2D recognition: This task aims at identifying both known and novel classes, where the labels of the known classes are available in the training set, while the novel classes are not encountered during training. In the direction of open-vocabulary object detection (OVOD), several approaches have been proposed [58, 36, 30, 53, 45, 22, 51, 7]. Another widely studied task is openvocabulary segmentation (OVSS) [3, 48, 27, 12, 28]. Recent open-vocabulary semantic segmentation methods [27, 12, 28] leverage pre-trained CLIP [55] to perform open-vocabulary segmentation, where the model is trained to output a pixel-wise feature that is aligned with the text embedding in the CLIP space. Furthermore, AttrSeg [33] proposes a decomposition-aggregation framework where vanilla class names are first decomposed into various attribute descriptions, and then different attribute representations are aggregated into a final class representation. Open-vocabulary instance segmentation (OVIS) aims at predicting instance masks while preserving high zero-shot capabilities. One approach [19] proposes a cross-modal pseudo-labeling framework, where a student model is supervised with pseudo-labels for the novel classes from a teacher model. Another approach [44] proposes an annotation-free method where a pre-trained vision-language model is used to produce annotations at both the box and pixel levels. Although these methods show high zero-shot performance and real-time speed, they are still limited to 2D applications only.
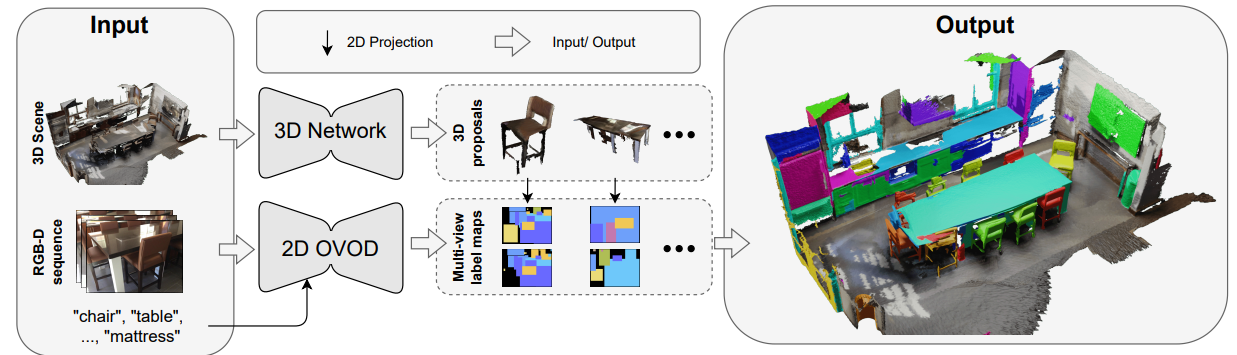
\ Open-vocabulary 3D segmentation: Several methods [35, 13, 16] have been proposed to address the challenges of open-vocabulary semantic segmentation where they use foundation models like clip for unknown class discovery, while the authors of [2] focus on weak supervision for unknown class discovery without relying on any 2D foundation model. OpenScene [35] makes use of 2D open-vocabulary semantic segmentation models to lift the pixel-wise 2D CLIP features into the 3D space, which allows the 3D model to perform 3D open-vocabulary point cloud semantic segmentation. On the other hand, ConceptGraphs [13] relies on creating an open-vocabulary scene graph that captures object properties such as spatial location, enabling a wide range of downstream tasks including segmentation, object grounding, navigation, manipulation, localization, and remapping. In the direction of 3D point cloud instance segmentation, OpenMask3D [42] uses a 3D instance segmentation network to generate class-agnostic mask proposals, along with SAM [23] and CLIP [55], to construct a 3D clip feature for each mask using RGB-D images associated with the 3D scene. Unlike OpenMask3D where a 3D proposal network is used, OVIR-3D [32] generates 3D proposals by fusing 2D masks obtained by a 2D instance segmentation model. Open3DIS [34] combines proposals from 2D and 3D with novel 2D masks fusion approaches via hierarchical agglomerative clustering, and also proposes to use point-wise 3D CLIP features instead of mask-wise features. The two most recent approaches in [34, 42] show promising generalizability in terms of novel class discovery [42] and novel object geometries especially small objects [34]. However, they both suffer from slow inference speed, as they rely on SAM for 3D mask proposal clip feature aggregation in the case of OpenMask3D [42], and for novel 3D proposal masks generation from 2D masks [34].
\ 
\
:::info Authors:
(1) Mohamed El Amine Boudjoghra, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) (mohamed.boudjoghra@mbzuai.ac.ae);
(2) Angela Dai, Technical University of Munich (TUM) (angela.dai@tum.de);
(3) Jean Lahoud, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) ( jean.lahoud@mbzuai.ac.ae);
(4) Hisham Cholakkal, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) (hisham.cholakkal@mbzuai.ac.ae);
(5) Rao Muhammad Anwer, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) and Aalto University (rao.anwer@mbzuai.ac.ae);
(6) Salman Khan, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) and Australian National University (salman.khan@mbzuai.ac.ae);
(7) Fahad Shahbaz Khan, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) and Australian National University (fahad.khan@mbzuai.ac.ae).
:::
:::info This paper is available on arxiv under CC BY-NC-SA 4.0 Deed (Attribution-Noncommercial-Sharelike 4.0 International) license.
:::
\


You May Also Like

The Ticketing Industry Is Breaking. Omar Sarieddine and Ticmint Are Betting on What Comes Next

PhilWeb inks deal with Newport for online gaming platform services




