

Stop Overpaying for AWS FSx: Enable Intelligent Tiering Today
AWS FSx has quickly become the go-to choice for organizations to host high-performance workloads in the cloud. Being a managed file storage service, it eliminates the hassle of filing server and storage infrastructure administration so that teams can concentrate on what is most important—their data and applications.
The service has been exploding in growth recently, led mainly by the growth of AI, machine learning, and HPC workloads. These use cases are of the type that need the kind of robust, high-performance file systems that FSx provides straight out of the box.
But there's a catch: while FSx excels on performance, it can also cut a deep chunk out of your cloud budget, especially when you're dealing with large volumes of data. The good news? There are several proven techniques to cut your FSx costs by half without sacrificing on performance - and we're about to explore them.
How does AWS FSx standout
Designed for Performance
When your workloads demand super-high-speed data access, FSx delivers. Whether rendering giant media files, simulating financial models, or crunching data for high-performance computing applications, FSx provides the high throughput and low-latency performance that keeps your operations running efficiently.
Scales with Your Demands
Begin small and think big - FSx file systems can scale to petabytes of storage and millions of IOPS. That means you're not locked into your initial storage decisions as your business expands and data requirements evolve.
Zero Infrastructure Headaches
Never mind having to worry about hardware, patching, or backup concerns. AWS handles all the behind-the-scenes tasks - from provisioning and maintenance to replication - so that your team can focus on innovation instead of infrastructure management.
Smart About Costs
FSx is not just about raw performance, but it is designed to be cost-effective as well. Through multiple deployment options and smart tiering capabilities, you can maximize your spending according to how frequently you actually access your data.
Plays Well with Others
FSx is not an island - it's completely integrated with your existing AWS environment. If you're connecting to EC2 instances, archiving to S3, or managing access with AWS Directory Service, it all works together with zero friction.
\
How Intelligent Tiering Makes the Magic Happen
FSx for Lustre with intelligent tiering operates cleverly since it uses Amazon S3 as its under-the-hood storage mate. Here's why and how the system accomplishes the magic:
The Hot Stuff: Your frequently accessed data sits on high-performance SSD storage—think of this as your desk drawer with everything you need right now. Access is supersnappy because the data is exactly where your applications are looking for it to be.
The Warm Archive: When files aren't accessed for a while, they are migrated automatically to Amazon S3 Standard-Infrequent Access (S3 Standard-IA). You're paying for pretty fast access, just at a lower price than SSD.
The Cold Storage: For those files that have completely gone dormant, the system can move files all the way to Amazon S3 Glacier Flexible Retrieval. This is your digital deep freeze—very inexpensive storage for data you might need someday but won't be accessing soon.
The good thing about this setup? Your applications don't know and don't care where the data's located. They request a file, and FSx handles all the back-end retrieving, whether it's from SSD or getting retrieved back from Glacier.
\ 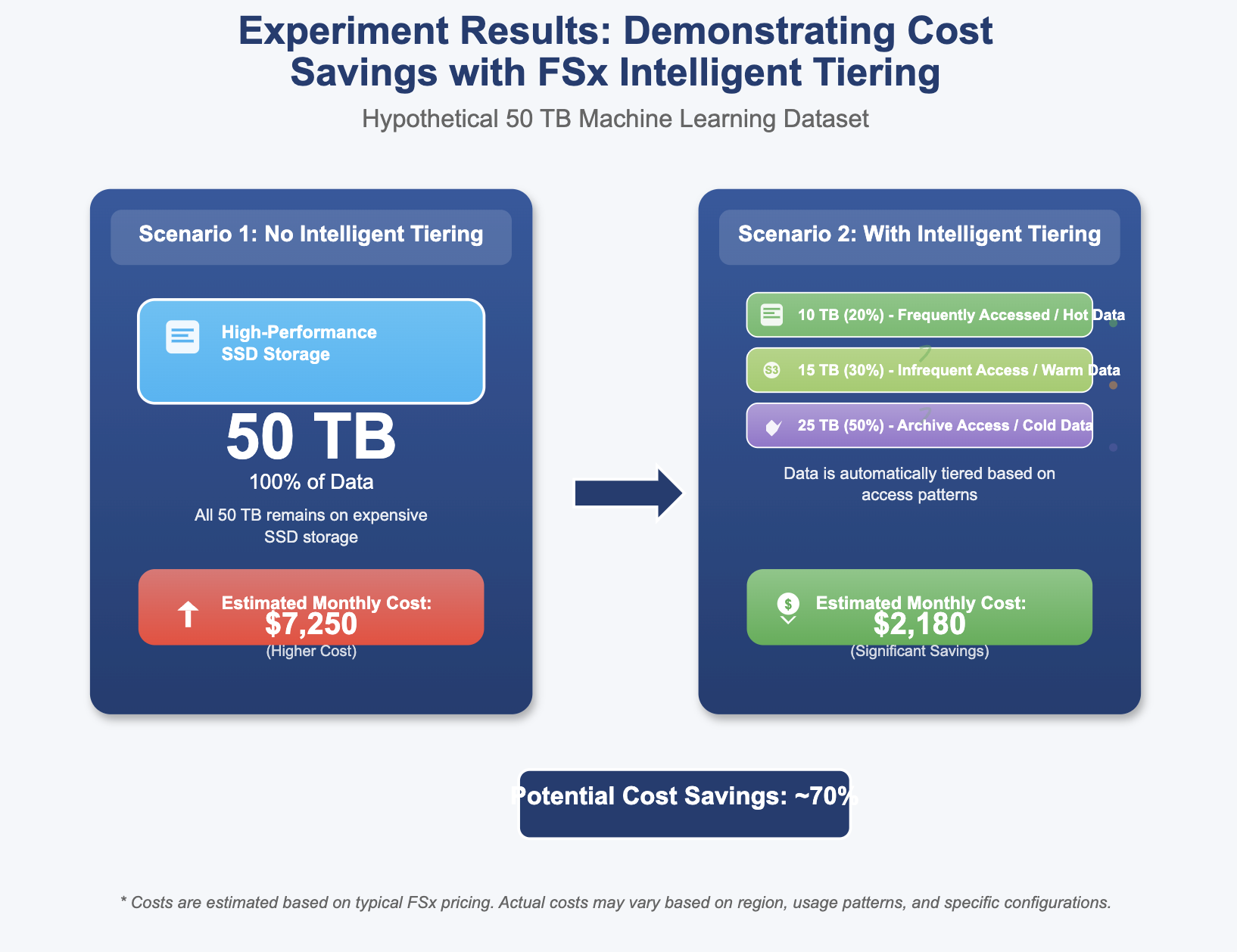
Our Experiment Setup
We compared two FSx for Lustre file systems: a baseline, high-performance Control system and a system with Intelligent Tiering enabled.
- Control System:
- Storage: 24 TiB
- Throughput: 1000 MB/s/TiB
- IOPS: 12,000 IOPS
- EFA: Enabled
- Intelligent Tiering System (IT):
- Cache: 4 TiB SSD read cache (this is where the "hot" data is stored)
- Throughput: 24,000 MB/s (This is the total provisioned throughput, independent of storage size, which is a key distinction with IT)
- IOPS: 12,000 IOPS
The IT system uses a much smaller capacity, faster SSD cache but leverages Amazon S3 for the vast majority of its storage. This is where the cost savings come from.
Experiment 1: Small Workload (200 GB)
For the first test, we used a lighter workload to simulate a single user or a few users building a new project. We had a total dataset size of 200 GB. We ran four common file operations and measured the average time for each.
| Operation | Control Mean Time (ms) | Intelligent Tiering Mean Time (ms) | % Difference | Result | |----|----|----|----|----| | gitclone (write) | 4970 | 5359 | 7.80% | PASS | | md5check (read) | 303482 | 307713 | 1.40% | PASS | | runtar (read+write) | 295072 | 296313 | 0.40% | PASS | | rununtar (write+read) | 244716 | 258263 | 5.50% | PASS |
\ As you can see, for this small workload, the performance of the intelligent tiering system was very close to the control system. The steps gitclone and rununtar, which are comprised of numerous file writes, did see a modest increase in time but were well within what was acceptable to our use case. All of these tests were tallied as a PASS because the performance difference was not perceptible. This was an indication to us that for smaller datasets that fit within the SSD cache, we could get great performance at much lower cost.
Experiment 2: Large Workload (32 TB)
The real challenge was with a much larger workload. We scaled up to a 32 TB dataset, simulating a massive data processing job or a full-scale machine learning training run. This test would heavily exercise the intelligent tiering's ability to handle data that won't all fit in the SSD cache.
\
| Operation | Control Mean Time (ms) | Intelligent Tiering Mean Time (ms) | % Difference | Result | |----|----|----|----|----| | gitclone (write) | 6943.75 | 13058.31 | 88% | FAIL | | md5check (read) | 1976316.77 | 1991334.67 | 0.80% | PASS | | runtar (read+write) | 2013425.76 | 1894051.99 | -5.90% | PASS | | rununtar (write+read) | 2109989.21 | 5874707.64 | 178.40% | FAIL |
\ The results of the large-scale test were eye-opening. It performed well on read-heavy operations like md5check, with the intelligent tiering system taking almost indistinguishably from the control. runtar also executed faster, likely because the new, compressed data was being written faster.
However, the write-heavy ones told a different tale. gitclone was a whopping 88% slower, and rununtar was a staggering 178.4% slower. The reason is simple: with the 32 TB dataset, the system had to go read cold data from S3 very frequently, and this came with a significant latency cost. While the S3 tier is great for cost savings, reading from it is inevitably slower than from the SSD cache. For I/O-bound workloads with a lot of random reads and writes, this can be a bottleneck.
What We Actually Learned
Having run these tests, we were left with a pretty clear picture: AWS FSx intelligent tiering is very useful, but it is not magic. Like most technology, it works extremely well if you use it for what it is designed to be used for.
The Sweet Spot
If your data can be contained within that 4 TiB SSD cache, you're golden. Our 200 GB test bore that out - performance was consistent while the prices dropped. It's perfect for teams that have smaller projects, dev environments, or anything where you're not constantly hammering the storage with massive write operations.
Where It Struggles
But throw 32 TB at it? That's where things go downhill - and not in a good way. Those write-heavy operations we benchmarked were completely bogged down, with some of them taking nearly three times as long. When your system is doing constant requests out to S3 to fetch data that's not in the cache, those milliseconds start adding up awfully fast.
The Real Question to Ask Yourself
Be honest with yourself before you enable intelligent tiering about how you actually use your data. Do you work with smaller datasets most of the time? Do you read files more frequently than writing new ones constantly? Then intelligent tiering can save you big bucks without even trying.
But if you're cranking up massive ML training jobs, grinding through gigantic datasets with loads of random access, or doing anything where predictable performance is an absolute requirement, stick with the old-school storage. Yeah, it's pricier, but you won't be pulling your hair out waiting for files to load.


You May Also Like

EdgeX (EDGE) Surges 46.6% to New ATH: Volume Analysis Reveals Unusual Pattern
Top Analyst Explains Why Robinhood Stock is Ripe for a Comeback




