

What the Heck is GizmoSQL?
Introduction
In my last installment of this series, I asked, “What the Heck is dbc?”, and that led to a conversation with Philip Moore, another Voltron Data alumnus who has founded GizmoData, where he is working on some pretty fascinating projects. One is GizmoEdge, which I might write up in the future, and the other is GizmoSQL, the subject of this article. What does it do? Why is it interesting? Why would you want it? Just what the heck is GizmoSQL?
Background
Let’s provide some background on the technology and projects involved. First, GizmoSQL is anopen-source SQL database engine and server powered by DuckDB and Apache Arrow Flight SQL. What is DuckDB? It was my first “What the Heck is…” article, and it has advanced significantly since then. It is an open-source, in-process analytical database engine designed for OLAP workloads, executing complex SQL queries directly within applications without requiring a separate server. Built with a columnar storage format and vectorized execution, it delivers high performance for large datasets across data analysis, ETL pipelines, and embedded analytics.
Apache Arrow Flight SQL is a protocol layered on Arrow Flight RPC that enables clients to execute standard SQL queries against remote database servers, with results streamed back in the efficient Arrow columnar in-memory format. It provides high-throughput, low-latency data transfer for analytical workloads, facilitating seamless integration with Arrow ecosystems such as Pandas, Polars, DuckDB, and data platforms that support the protocol.
Apache Arrow Flight SQL is part of the Apache Arrow ecosystem, which itself is a cross-language in-memory analytics platform that provides a standardized columnar memory format. It eliminates serialization and deserialization when moving data between systems and programming languages, enabling zero-copy reads and efficient data sharing.
That’s all, some pretty cool, and potentially confusing tech to dive into, and that is what makes GizmoSQL interesting: getting that power and reducing the complexity.
What is GizmoSQL?
Broken down to its basics, GizmoSQL is a small server that runs DuckDB, with the Arrow Flight SQL protocol wrapped around it so that you can run DuckDB remotely. Why would you want to do that? DuckDB is a fantastic engine; you can run it on your laptop and handle billions of rows, for example. Now imagine it’s running in a VM on a cloud service where you can allocate insane numbers of cores and RAM, and you're now talking trillions of rows. I’m told they did the Trillion Row Challenge in 2 minutes for 9 cents with this configuration.
With all that background, it's time to dig in with copious screenshots.
Digging in
There is a free demo available with the TPC-H data set preloaded and a couple of dozen prewritten queries for you to test. In our first screenshot, this is the default view when you first get in, and you can just execute the query. A nifty little feature here is your query history, which includes execution time. You can see I did a few things already, but also note that just clicking on a query in the history will load it back into the SQL window, no need to copy/paste.
The customer table here has 1.5 million rows, and I wrote a query to count all records where c_nationkey is 15. It returned 60,000 in 154ms. That’s pretty speedy. Let’s look at some of the included queries:
 We’ll try Query 22, Global Sales Opportunity:
We’ll try Query 22, Global Sales Opportunity:
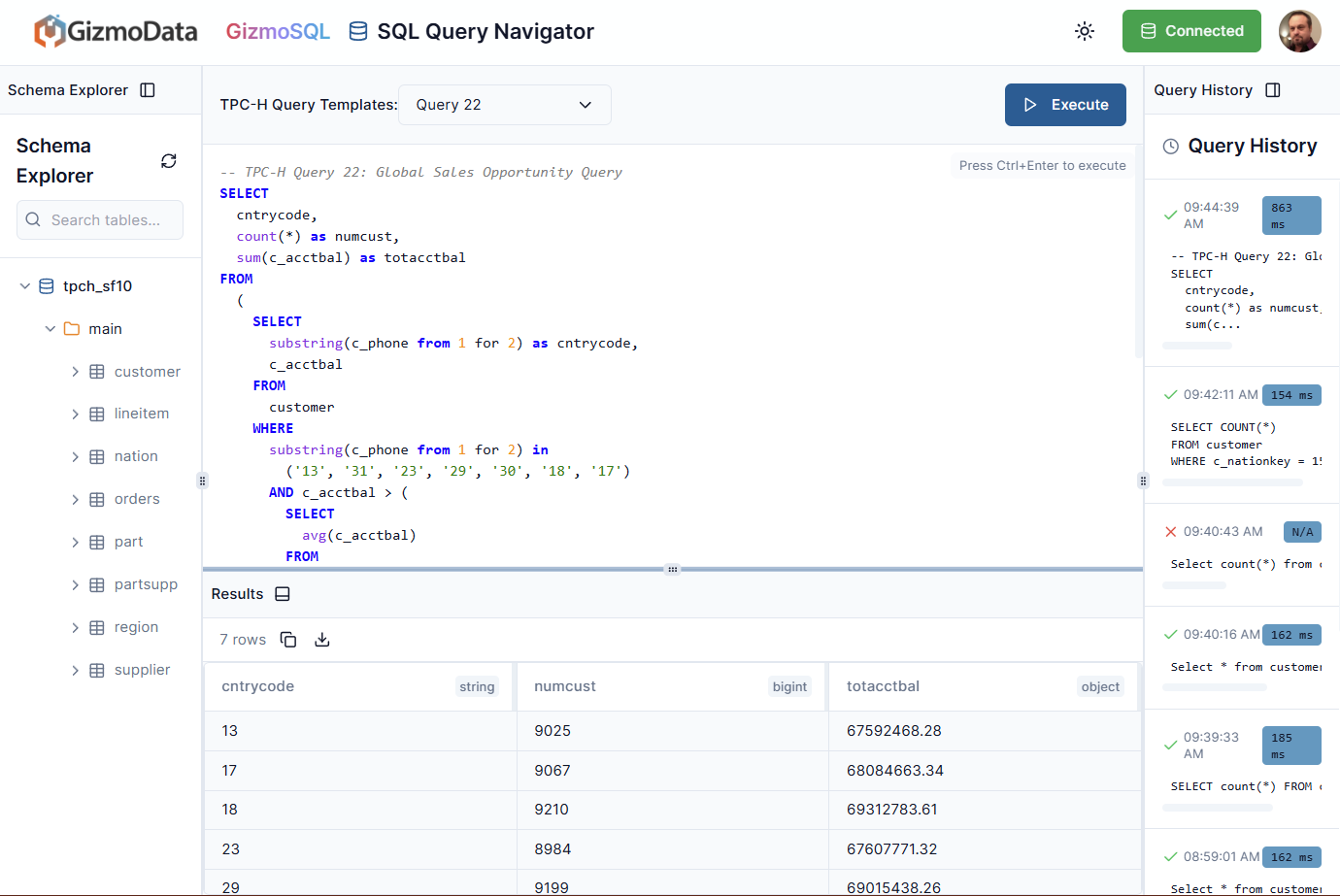 You can see that it was executed in under a second, with a lot of processing going on, which is pretty impressive. Let’s look at one more where a lot of tables and filters are taking place, this is Query 2:
You can see that it was executed in under a second, with a lot of processing going on, which is pretty impressive. Let’s look at one more where a lot of tables and filters are taking place, this is Query 2:
That finished off in about a half second. Which is just crazy fast.
I’ve been doing stuff like this since the early 80s, and it blows my mind how database technology has evolved. We used to have to play a lot of tricks to get things to run fast, but runs that took hours were not uncommon. I had one year-end process that took 10 days to run. I wrote some operating system intercepts to optimize it and got it down to 4 hours, and even that amount of time in today’s world seems crazy long.
Summary
What GizmoData has done here is combine some technology, done some innovation on top of it, and made a stupidly simple product that gives you unbelievable speed and ease of use. I didn’t talk about loading data, because that’s kind of boring to watch. The service supports every cloud platform, including OCI. Is it sort of like MotherDuck? Yes, it is, but it is also different in how Arrow Flight SQL is integrated. Does this fit in your stack? That’s up to you to decide, of course, but there is a pretty good selection of Integrations and Adapters that open things up for you.
This is clever, and I like clever things. If I were still in the private sector, I’d be using this kind of thing all the time. I don’t want to cheerlead too much when I run across new tech, but when I find something that would have made my life much easier, I can gush a bit.
Want to read more in my “What the Heck is???” series? A handy list is below:
- What The Heck Is DuckDB?
- What the Heck Is Malloy?
- What the Heck is PRQL?
- What the Heck is GlareDB?
- What the Heck is SeaTunnel?
- What the Heck is LanceDB?
- What the heck is SDF?
- What the Heck is Paimon?
- What the Heck is Proton?
- What the Heck is PuppyGraph?
- What the Heck is GPTScript?
- What the Heck is WarpStream?
- What the Heck is DeltaStream?
- What the Heck is OpenMetadata?
- What the Heck is dbc?
\
Ayrıca Şunları da Beğenebilirsiniz

The Channel Factories We’ve Been Waiting For

Solana Prepares Major Consensus Upgrade with Alpenglow Protocol
