

Drop the Heavyweights: YOLO‑Based 3D Segmentation Outpaces SAM/CLIP
Table of Links
Abstract and 1 Introduction
- Related works
- Preliminaries
- Method: Open-YOLO 3D
- Experiments
- Conclusion and References
A. Appendix
3 Preliminaries
Problem formulation: 3D instance segmentation aims at segmenting individual objects within a 3D scene and assigning one class label to each segmented object. In the open-vocabulary (OV) setting, the class label can belong to previously known classes in the training set as well as new class labels. To this end, let P denote a 3D reconstructed point cloud scene, where a sequence of RGB-D images was used for the reconstruction. We denote the RGB image frames as I along with their corresponding depth frames D. Similar to recent methods [35, 42, 34], we assume that the poses and camera parameters are available for the input 3D scene.
\
3.1 Baseline Open-Vocabulary 3D Instance Segmentation
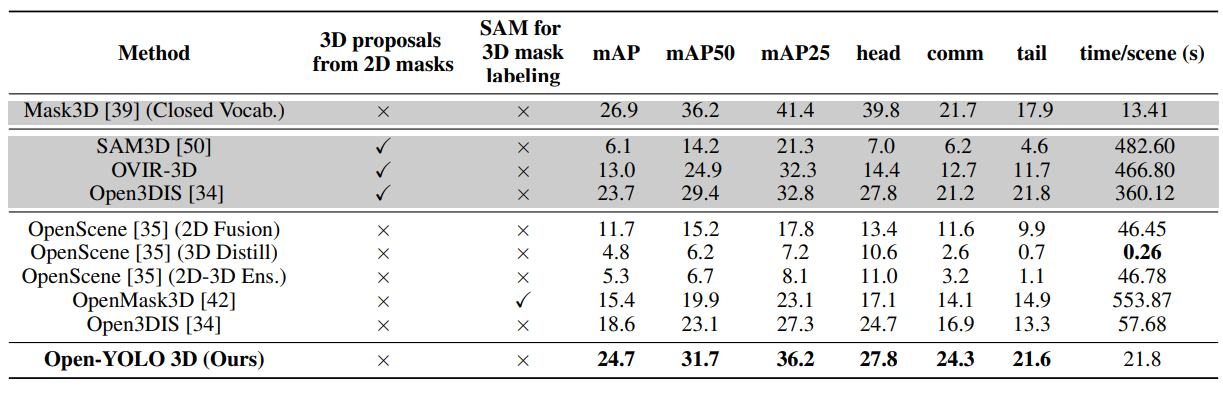
We base our approach on OpenMask3D [42], which is the first method that performs open-vocabulary 3D instance segmentation in a zero-shot manner. OpenMask3D has two main modules: a class-agnostic mask proposal head, and a mask-feature computation module. The class-agnostic mask proposal head uses a transformer-based pre-trained 3D instance segmentation model [39] to predict a binary mask for each object in the point cloud. The mask-feature computation module first generates 2D segmentation masks by projecting 3D masks into views in which the 3D instances are highly visible, and refines them using the SAM [23] model. A pre-trained CLIP vision-language model [55] is then used to generate image embeddings for the 2D segmentation masks. The embeddings are then aggregated across all the 2D frames to generate a 3D mask-feature representation.
\ Limitations: OpenMask3D makes use of the advancements in 2D segmentation (SAM) and vision-language models (CLIP) to generate and aggregate 2D feature representations, enabling the querying of instances according to open-vocabulary concepts. However, this approach suffers from a high computation burden leading to slow inference times, with a processing time of 5-10 minutes per scene. The computation burden mainly originates from two sub-tasks: the 2D segmentation of the large number of objects from the various 2D views, and the 3D feature aggregation based on the object visibility. We next introduce our proposed method which aims at reducing the computation burden and improving the task accuracy.
\
4 Method: Open-YOLO 3D
Motivation: We here present our proposed 3D open-vocabulary instance segmentation method, Open-YOLO 3D, which aims at generating 3D instance predictions in an efficient strategy. Our proposed method introduces efficient and improved modules at the task level as well as the data level. Task Level: Unlike OpenMask3D, which generates segmentations of the projected 3D masks, we pursue a more efficient approach by relying on 2D object detection. Since the end target is to generate labels for the 3D masks, the increased computation from the 2D segmentation task is not necessary. Data Level: OpenMask3D computes the 3D mask visibility in 2D frames by iteratively counting visible points for each mask across all frames. This approach is time-consuming, and we propose an alternative approach to compute the 3D mask visibility within all frames at once.
\
4.1 Overall Architecture

\
4.2 3D Object Proposal

\
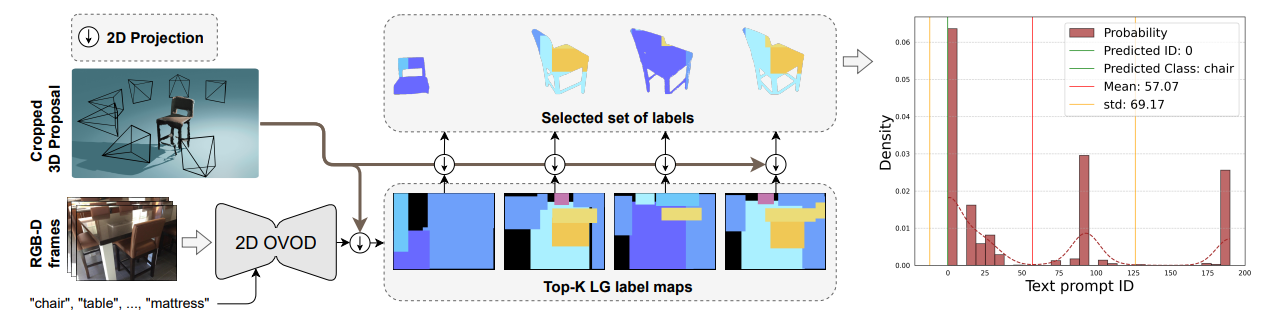
4.3 Low Granularity (LG) Label-Maps

\
4.4 Accelerated Visibility Computation (VAcc)
In order to associate 2D label maps with 3D proposals, we compute the visibility of each 3D mask. To this end, we propose a fast approach that is able to compute 3D mask visibility within frames via tensor operations which are highly parallelizable.
\ 
\ 
\ 
\
4.5 Multi-View Prompt Distribution (MVPDist)

\ 
\
4.6 Instance Prediction Confidence Score

\
:::info Authors:
(1) Mohamed El Amine Boudjoghra, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) (mohamed.boudjoghra@mbzuai.ac.ae);
(2) Angela Dai, Technical University of Munich (TUM) (angela.dai@tum.de);
(3) Jean Lahoud, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) ( jean.lahoud@mbzuai.ac.ae);
(4) Hisham Cholakkal, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) (hisham.cholakkal@mbzuai.ac.ae);
(5) Rao Muhammad Anwer, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) and Aalto University (rao.anwer@mbzuai.ac.ae);
(6) Salman Khan, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) and Australian National University (salman.khan@mbzuai.ac.ae);
(7) Fahad Shahbaz Khan, Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI) and Australian National University (fahad.khan@mbzuai.ac.ae).
:::
:::info This paper is available on arxiv under CC BY-NC-SA 4.0 Deed (Attribution-Noncommercial-Sharelike 4.0 International) license.
:::
\
Ayrıca Şunları da Beğenebilirsiniz

Polygon Tops RWA Rankings With $1.1B in Tokenized Assets

XRP Stuns ETF Market With Strange $0 Print in Biggest Fund
