

Beyond Preprocessing: Sequential Indexing and Temporal Consistency in IA2
Table of Links
Abstract and 1. Introduction
-
Related Works
2.1 Traditional Index Selection Approaches
2.2 RL-based Index Selection Approaches
-
Index Selection Problem
-
Methodology
4.1 Formulation of the DRL Problem
4.2 Instance-Aware Deep Reinforcement Learning for Efficient Index Selection
-
System Framework of IA2
5.1 Preprocessing Phase
5.2 RL Training and Application Phase
-
Experiments
6.1 Experimental Setting
6.2 Experimental Results
6.3 End-to-End Performance Comparison
6.4 Key Insights
-
Conclusion and Future Work, and References
5.2 RL Training and Application Phase
The RL Training and Application Phase of IA2 transitions from initial preprocessing to actively engaging with defined action spaces and state representations, marked by:
\ TD3-TD-SWAR Algorithm Application: Leveraging the action space and state representations crafted in the preprocessing phase, IA2 employs the TD3-TD-SWAR algorithm, as outlined in Algorithm 1. Unlike merely operating on preprocessed data, this approach integrates action space restrictions—accounting for existing index candidates and their masking history. Each tuning step recalibrates masking
\ 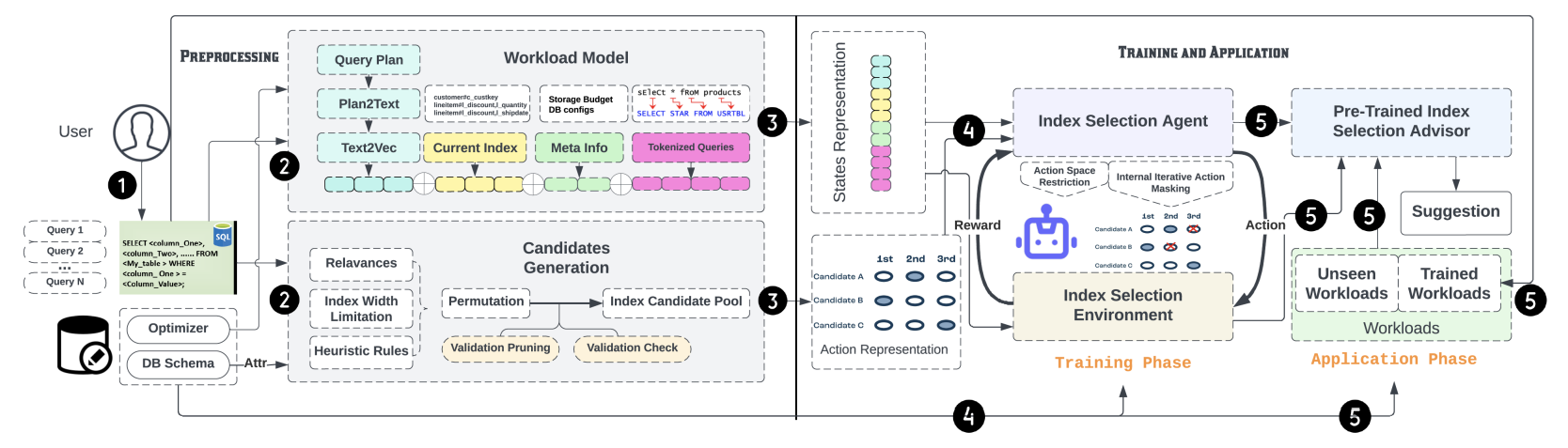
\ possibilities for subsequent selections, embodying a strategy that adaptively masks actions irrelevant based on the current agent states.
\ Adaptation to Workloads: Designed for flexibility, IA2 applies learned strategies to a range of workloads, efficiently adapting to both familiar and unseen environments, demonstrating its capability to handle diverse operational scenarios.
\
:::info Authors:
(1) Taiyi Wang, University of Cambridge, Cambridge, United Kingdom (Taiyi.Wang@cl.cam.ac.uk);
(2) Eiko Yoneki, University of Cambridge, Cambridge, United Kingdom (eiko.yoneki@cl.cam.ac.uk).
:::
:::info This paper is available on arxiv under CC BY-NC-SA 4.0 Deed (Attribution-Noncommercial-Sharelike 4.0 International) license.
:::
\


You May Also Like

Stop Losing Sales in 2026: Build Better Funnels with Checkout Champ

Top Mistakes People Make When Choosing Web Hosting




