

Solana presents a new way to play MEV, with atomic arbitrage accounting for half of the transactions. Is it a hidden vault or a new sickle?
Author: Frank, PANews
As various DEXs began to provide personalized priority fee options and anti-sandwich measures, the income from sandwich attacks on Solana has declined significantly. As of May 6, this figure has dropped to 582 SOLs, while a few months ago, the average daily income of a single sandwich attack robot could basically reach 10,000 SOLs. But this is not the end of MEV, a new type of atomic arbitrage is becoming the main source of transactions on the Solana chain.
According to data from sandwiched.me, the proportion of atomic arbitrage on the chain has reached an exaggerated level. On April 8, the tip ratio contributed by atomic arbitrage reached 74.12%, and at other times, it basically remained above 50%. In other words, now for every two transactions on the Solana chain, one may be used for atomic arbitrage.
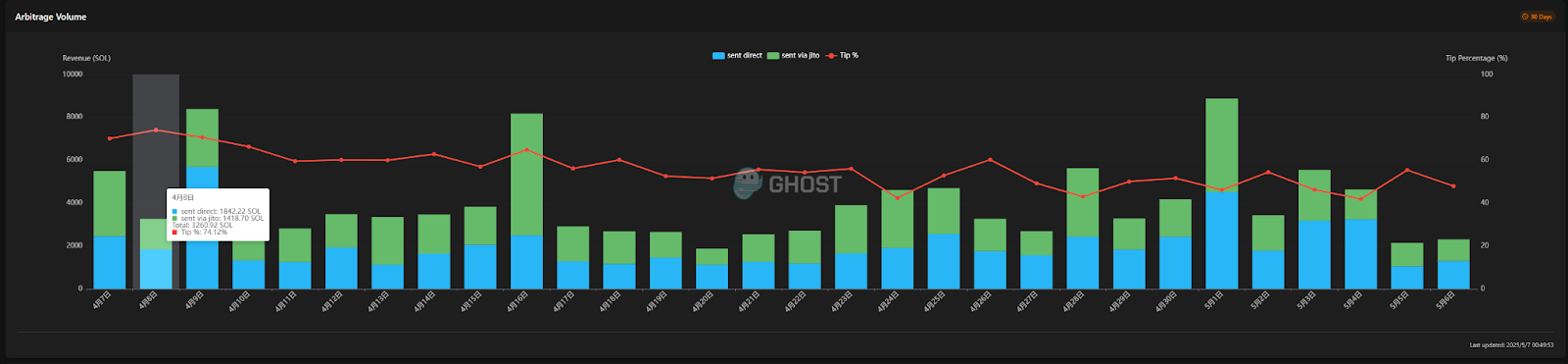
But there is almost no discussion of atomic arbitrage on social media. Is this new type of arbitrage opportunity a hidden treasure trove or just another fancy sickle?
Atomic arbitrage, a new way of trading MEV
First, let's understand what atomic arbitrage is? Atomic arbitrage refers to the execution of multiple-step arbitrage operations in a single, atomic blockchain transaction. Typical atomic arbitrage involves buying an asset at a lower price on a decentralized exchange (DEX) and then selling the asset at a higher price on another DEX in the same transaction. Since the entire process is encapsulated in a single atomic transaction, it naturally eliminates the counterparty risk and part of the execution risk present in traditional cross-exchange arbitrage or non-atomic arbitrage. If the transaction is successful, the profit will be locked in; if the transaction fails, in addition to the loss of transaction fees, the arbitrageur's asset status will be restored to its original state, and there will be no situation where only the purchase is completed but the sale is not completed.
Atomicity is not a feature designed for arbitrage, but a fundamental property inherent in blockchain to ensure state consistency. Arbitrageurs cleverly exploit this guarantee to bundle operations (buy, sell) that originally need to be executed step by step and carry execution risks into one atomic unit, thereby eliminating execution risks at the technical level.
In the past, sandwich attacks or automated trading robots focused on finding profitable opportunities in the same trading pair. They then sandwiched the opponent's transactions in the middle by means of packaged transactions or simply sent transactions one after another to create opportunities. Atomic arbitrage is essentially also a packaged transaction method, but it focuses more on finding price differences in multiple trading pools to obtain arbitrage opportunities.
The myth of huge profits and the cruel reality
Judging from the current data, this kind of atomic arbitrage seems to have a good profit margin. In the past month, atomic arbitrage on the Solana chain has made a profit of 120,000 SOL (worth about 17 million US dollars), and the address with the most profit only spent 128.53 SOL, and the profit reached 14,129 SOL, with a return rate of 109 times. The largest single profit only cost 1.76 SOL and earned 1,354 SOL, with a single return rate of 769 times.
There are currently 5,656 atomic arbitrage robots in the statistics, with an average profit of 24.48 SOL (3,071 USD) per address and an average cost of about 870 USD. Although this value is not as high as the previous sandwich attacker, it seems to be a good business idea, after all, the monthly return rate can reach 352%.
However, it is worth noting that the costs shown here are only the costs of on-chain transactions. Atomic arbitrage requires more investment.
According to the webpage information made by a MEV developer, there are several hardware requirements for performing atomic arbitrage, including a private RPC and an 8-core 8G server. From a cost perspective, the cost of a server is between $100 and $300 per month, and the minimum cost of building a private server is about $50 per month. The overall monthly cost is around $150 to $500, and this is just the minimum threshold. In addition, in order to perform arbitrage faster, servers with multiple IP addresses are usually configured at the same time.
From an example, we can see on a certain atomic arbitrage deployment website that only 15 addresses have earned more than 1 SOL in the past week, with the largest being 15 SOL. The other addresses have earned less than 1 SOL in the past week, and many are in a loss-making state. If we take into account the server and node costs, basically all the robots on this platform may be in a loss-making state. And it can be clearly seen that many addresses have chosen to stop arbitrage.
Who is making a profit? Uncovering the mystery of arbitrage that is “guaranteed to make a profit”
Of course, reality seems to conflict with big data. From the overall data, the robots that perform atomic arbitrage on Solana are still profitable. This is also difficult to escape the constraints of the "80/20 rule". A few high-level arbitrage robots have obtained a lot of profits. The others are still reduced to new leeks.
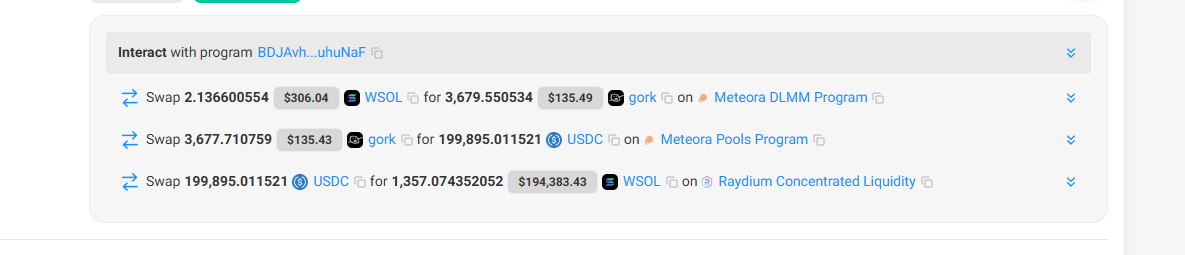
Looking back at the overall logic of atomic arbitrage, it is not difficult to find that the most important point to achieve profitability is to find arbitrage opportunities. Taking the most profitable arbitrage as an example, this transaction initially used 2.13 SOL to purchase 3,679 grok tokens (at a unit price of about $0.08), and then sold them for $199,000 (at a unit price of about $54.36). Obviously, the success of this arbitrage also seized the loophole of scarce liquidity in a certain trading pool, and was paid by a large investor who did not pay attention to the depth of the pool.

But in essence, such opportunities are rare, and since almost all robots on the chain are eyeing similar opportunities, such occasional large arbitrage opportunities are more like winning the lottery.
The recent rise of atomic arbitrage may be due to some developers packaging this arbitrage opportunity as a sure-win business and developing a free version for novice users to use for free, and providing tutorials. They only receive 10% of the profits when the arbitrage is profitable. In addition, these teams also charge subscription fees by assisting in setting up nodes and servers, and providing more IP services.
In fact, since most users do not have a deep understanding of the technology and use similar arbitrage opportunity monitoring tools, the profits they make are not much and cannot cover the basic expenses.
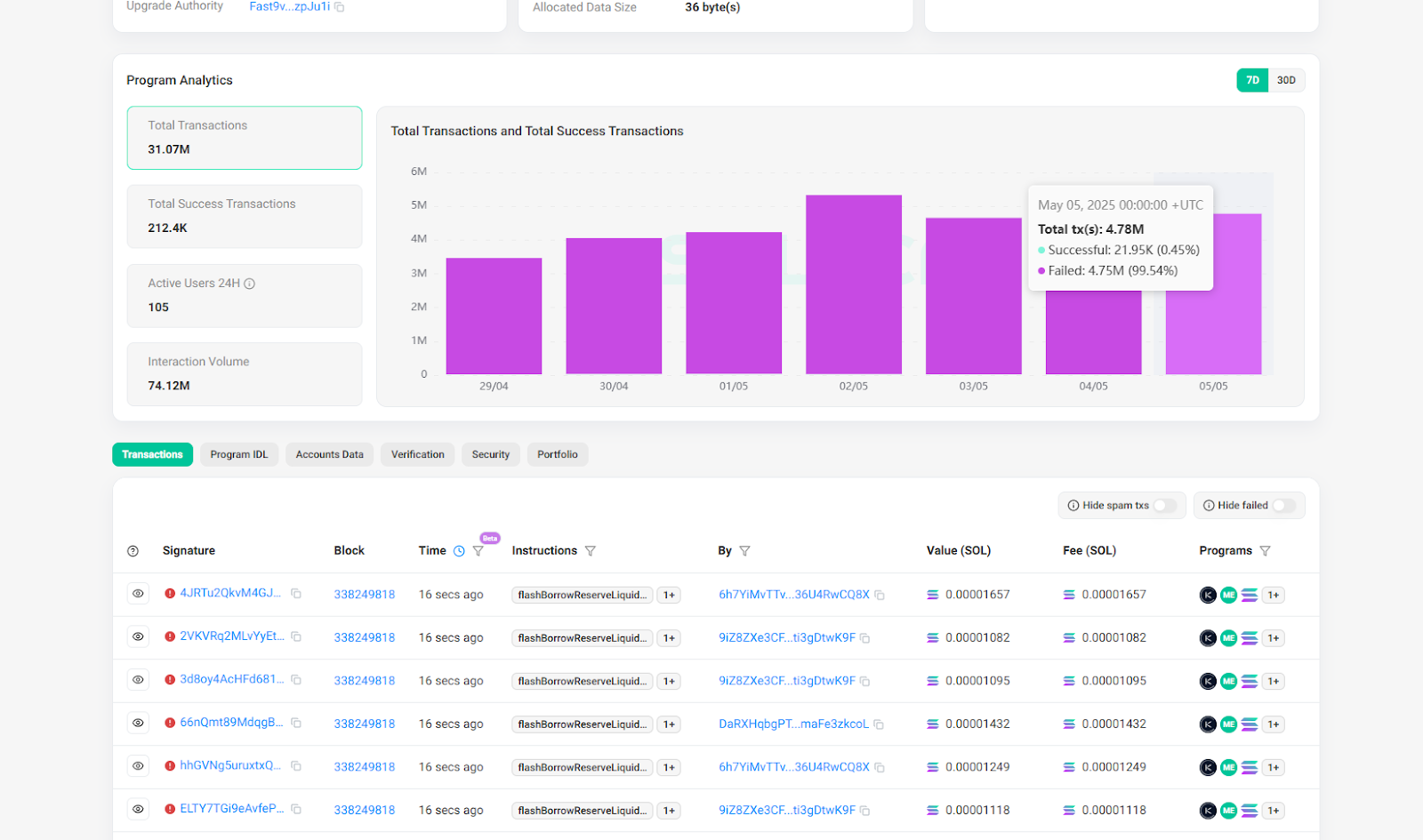
According to PANews’ observation, unless you have a certain technical foundation, unique arbitrage opportunity monitoring tools, and high-performance servers and nodes, most players who want to participate in atomic arbitrage are simply being cheated by buying servers and subscription fees instead of being cut from speculating in coins. And as more and more people participate, the probability of this arbitrage failure is also increasing. Take the highest-yielding program on sandwiched.me as an example. The program’s current transaction failure rate has reached more than 99%, which means that basically all transactions have failed, and the participating robots still have to pay on-chain fees.
Before plunging into this seemingly tempting wave of "atomic arbitrage", every potential participant should keep a clear head, fully evaluate their own resources and capabilities, be wary of over-packaged promises of "guaranteed profits", and avoid becoming another wave of leeks in this new "gold rush".
Ayrıca Şunları da Beğenebilirsiniz

South Korea Launches Innovative Stablecoin Initiative

Trump Cancels Tech, AI Trade Negotiations With The UK
