

Behind Injective’s soaring data, is it a flash in the pan or a comeback?
Author: Frank, PANews
In the past month, the old public chain Injective has returned to the public eye again with the second-highest net inflow of funds. According to Artemis data, Injective has a net inflow of about 142 million US dollars in the past 30 days, only lower than Ethereum.
PANews also observed other data of Injective and found that this phenomenon of net capital inflow is not a single case. There have been significant increases in on-chain fees, active users, token trading volume, etc. After a long period of silence, will this former public chain rising star Injective usher in another ecological explosion? Or is it just a short-lived flash in the pan?
With a monthly inflow of US$142 million, are high returns "honey" or "flares"?
Data as of June 4 shows that Injective has achieved a net inflow of $142 million in the past month. Although the amount is not high, it still ranks second among all public chains in recent data. A closer look at the data shows that the obvious reason for this net inflow is that Injective has indeed ushered in a wave of rapid and large capital inflows on the one hand, and on the other hand, the net outflow of funds is very small, only $11 million. Therefore, if we look into the reasons, Injective's high ranking in net inflow this time is not because its overall capital flow is abnormally active (that is, there are large-scale capital inflows and outflows at the same time). In fact, its pure capital inflow is only ranked around tenth in a horizontal comparison with other public chains. The key to its outstanding performance in the "net inflow" indicator is that the capital outflow during the same period is negligible.
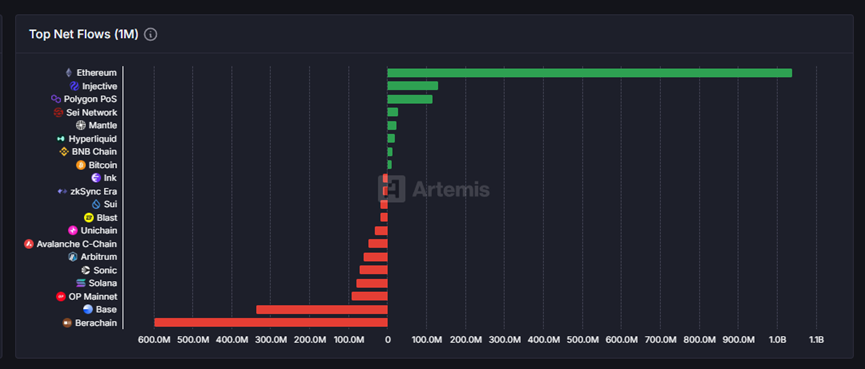
However, this kind of abnormal movement of funds on the chain is also rare for the Injective network. Of the 142 million inflows, 140 million was completed through the peggy cross-chain bridge, accounting for 98.5% of the share. Market analysis agency Keyrock pointed out in its report "Key Insights, Bond Appetit" released on May 26 that this large-scale inflow of funds was mainly attributed to the launch of the institutional-level yield platform Upshift on Injective. It is understood that Upshift's vault APY on Injective has reached 30%, and this high yield may indeed be an important reason for attracting funds to transfer assets to Injective.
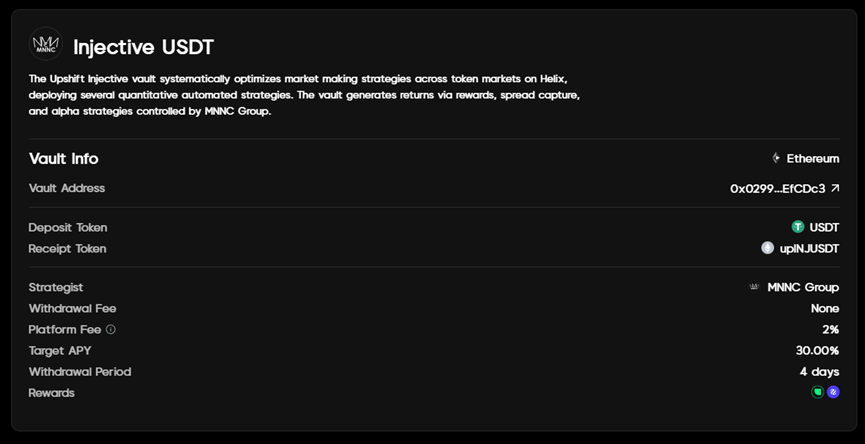
However, PANews found through investigation that the hard cap of the vault established by Upshift at Injective is US$5 million, which cannot fully accommodate the inflow of this part of funds. Those funds that failed to participate in this vault investment may be lost again in the short term.
From the failure of derivatives to the hope of RWA, can Injective create a new situation?
In addition to the inflow of funds, Injective has also recently ushered in some important changes in the ecosystem. On April 22, the Lyora mainnet was officially launched. This upgrade is an important milestone in the development of Injective. After this mainnet upgrade, technical optimizations such as dynamic fee structure and smart memory pool were introduced. According to official information, after the upgrade, Injective is described as "faster" and claims to have lower latency and higher throughput.
In addition, Injective has also launched iAssets, an oracle framework specifically for RWA. Upshift’s vault is an RWA DeFi vault. On May 29, Injective officially announced the launch of the on-chain foreign exchange market for the euro and the pound, using the iAsset framework. From this perspective, Injective’s new narrative seems inseparable from RWA.
As an old public chain, the original core narrative of Injective was a decentralized derivatives exchange. The original Injective also evolved from a decentralized derivatives exchange to a public chain, and this route seems to be exactly the same as that of Hyperliquid, which is in the limelight today.
However, Injective's current derivatives trading seems to have failed to achieve the expected goals. Data from June 4 showed that the BTC contract pair with the highest trading volume on Injective within 24 hours had a trading volume of approximately US$39.75 million, and the total derivatives trading volume of the entire chain was approximately US$90 million. In comparison, Hyperliquid's data for the same day was approximately US$7 billion, a difference of approximately 77 times.
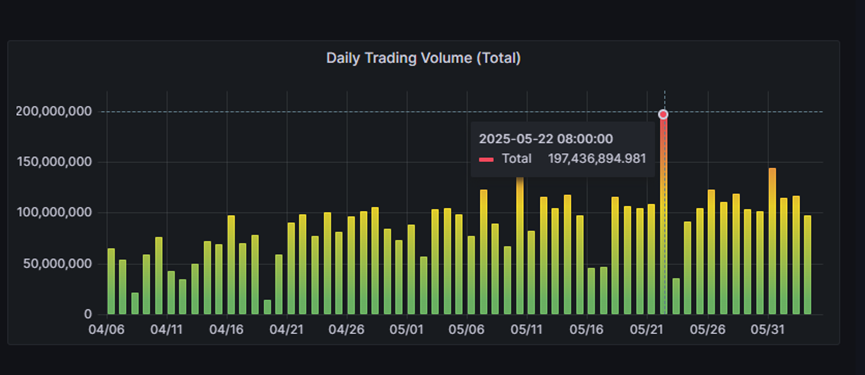
Perhaps because it was difficult to open up the market in crypto derivatives, Injective chose to turn to the direction of RWA integration. From the perspective of the development of the ecosystem itself, this transformation seems to have a certain effect. On May 22, Injective's derivatives transactions reached a peak of US$1.97 billion, significantly higher than other times, and have shown an overall upward trend in the near future.
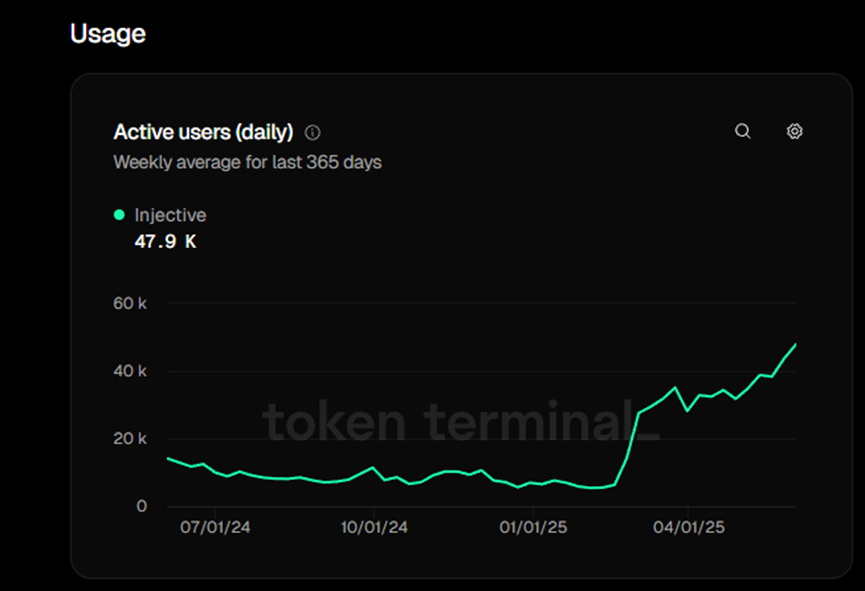
In addition, in terms of daily active users, the number of addresses has surged from the lowest of 6,300 in February to 47,900 recently, an increase of about 7.6 times. Although this data ranks only 12th among all public chains, considering the rapid growth in the short term and surpassing public chains such as Avalanche and Berachain, it is also a relatively obvious breakthrough.
However, even though the daily activity has increased significantly, the TVL of Injective has not changed significantly. It has been declining since March 2024, and the current TVL is only 26.33 million US dollars. At least for now, the DeFi projects on Injective are still not very attractive to funds.
The token's performance rebounded significantly in the short term, but it is still 4 times away from its historical high
In terms of economy, the market value of its governance token INJ is currently about $1.26 billion, ranking 82nd. Compared with the highest market value of $5.3 billion, it has fallen by 76%. However, it has rebounded from the lowest point of $6.34 in April to $15.48, an increase of 144%. This data is also relatively impressive among the old public chains. However, it is still unknown how long this performance can be sustained. 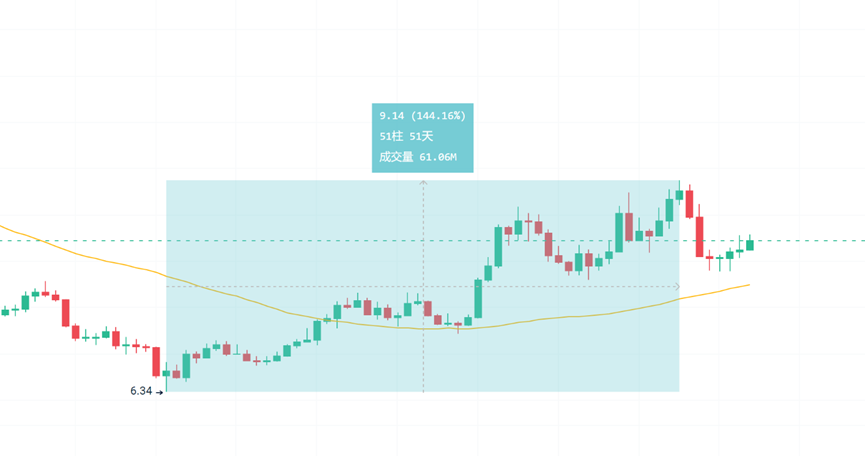
Of course, Injective's recent actions are not limited to the above. For example, it has recently attracted many well-known institutions such as Republic, Google Cloud, and Deutsche Telekom MMS to join the ranks of validators, and launched some AI-related products and dynamics. Overall, Injective has been actively seizing new narratives such as AI and RWA to transform in the past year. According to the data as of June, it has indeed achieved some growth in recent months. However, in terms of order of magnitude, it is still far behind the current mainstream public chains.
Injective is not the only one catching up. Several star public chains in the last round are now facing similar dilemmas. Many of them have returned to the public eye by changing their names and upgrading their brands. However, can this model of putting old wine in new bottles really give the market a new taste, or can it only stay in a brand new packaging?
At present, Injective's ecological transformation and revival are still in their infancy. The capital inflow triggered by Upshift is more like an important market sentiment test and ecological potential demonstration, rather than a fundamental reversal of the pattern. Whether its strategic inclination towards RWA can truly open up a differentiated competitive advantage and transform into sustained ecological prosperity and value capture still needs to overcome many challenges and be subject to long-term market testing.
Only time will tell whether the short-term data rebound is a flash in the pan or a positive signal in the long journey of recovery. For Injective, the real test has just begun.
Ayrıca Şunları da Beğenebilirsiniz

South Korea Launches Innovative Stablecoin Initiative

Trump Cancels Tech, AI Trade Negotiations With The UK
