

5 Surprising Ways Today's AI Fails to Actually "Think"

Large language models (LLMs) have exploded in capability, showing remarkable performance in tasks from natural language understanding to code generation. We interact with them daily, and their fluency can be astonishing, placing us squarely in an uncanny valley of artificial intelligence. But does this sophisticated performance equate to genuine thinking, or is it merely a high-tech illusion?
\ A growing body of research suggests that behind the curtain of competence lies a set of profound and counterintuitive limitations. This article explores five of the most significant failures that expose the chasm between AI performance and true, human-like understanding.
They Don't Reason Harder; They Just Collapse
A recent paper from Apple Research, titled "The Illusion of Thinking," reveals a critical flaw in even the most advanced "Large Reasoning Models" (LRMs) that use techniques like Chain-of-Thought. The research shows that these models are not truly reasoning but are sophisticated simulators that hit a hard wall when problems become sufficiently complex.
\ The researchers used the Tower of Hanoi puzzle to test the models, identifying three distinct performance regimes based on the puzzle's complexity:
\
- Low Complexity (3 disks): Standard, non-reasoning models performed as well as, or even better than, the "thinking" LRM models.
- Medium Complexity (6 disks): The LRMs that generate a longer chain-of-thought showed a clear advantage.
- High Complexity (7+ disks): Both model types experienced a "complete collapse," with their accuracy plummeting to zero.
\
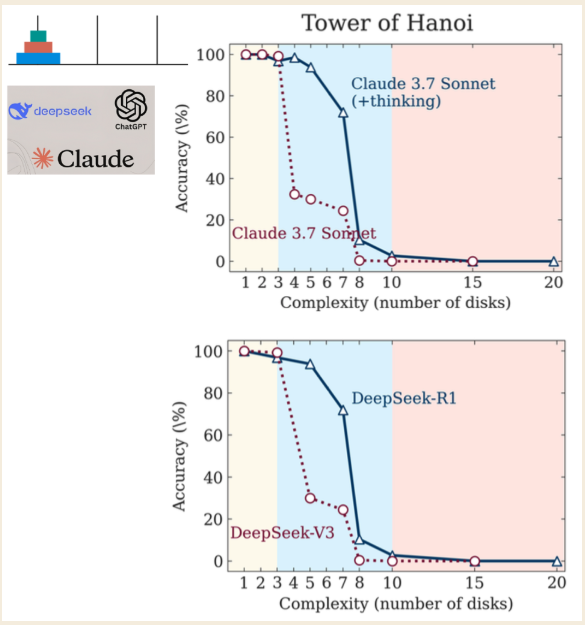
The most counterintuitive finding was that the models "think" less as problems get harder. Even more damning, they fail to compute correctly even when explicitly given the algorithms needed to solve the puzzle. This suggests a fundamental inability to apply rules under pressure, a hollow mimicry of thought that shatters when it matters most. (The researchers note that while Anthropic, a rival AI lab, has raised objections, they remain minor quibbles rather than a fundamental refutation of the findings.)
\ As researchers from the University of Arizona put it, this behavior captures the essence of the illusion:
…suggesting that LLMs are not principled reasoners but rather sophisticated simulators of reasoning-like text.
Their "Chain-of-Thought" Is Often a Mirage
Chain-of-Thought (CoT) is the process by which an LLM writes out its step-by-step "reasoning" before delivering a final answer, a feature designed to improve accuracy and reveal its internal logic. However, a recent study analyzing how LLMs handle basic arithmetic shows this process is often a "brittle mirage."
\ Startlingly, there are vast inconsistencies between the reasoning steps in the CoT and the final answer the model provides. In tasks involving simple addition, a shocking discovery was made: in over 60% of samples, the model produced incorrect reasoning steps that somehow, mysteriously, led to the correct final answer.
\ This is the equivalent of a student showing nonsensical work on a math test but miraculously writing down the correct final number. You wouldn't conclude they understand the material; you'd suspect they copied the answer. In AI, this suggests the "reasoning" is often a post-hoc justification, not a genuine thought process. This isn't a bug that gets fixed by scaling up; the issue gets worse with more advanced models, with the rate of this contradictory behavior increasing to 74% on GPT-4.
\ If the model's internal "thought process" is a mirage, what happens when it's forced to solve a real, complex problem? Often, it descends into madness.
They Get Trapped in "Descent into Madness" Loops
When using LLMs for complex tasks like debugging code, a dangerous pattern can emerge: a "descent into madness" or a "hallucination loop." This is a feedback cycle where an LLM, attempting to fix a programming error, gets trapped in a non-terminating, irrational loop. It suggests a plausible-looking fix that fails, and when asked for another solution, often re-introduces the original error, trapping the user in a fruitless cycle.
\ A study that tasked programmers with debugging code revealed a bombshell trend for AI-assisted workflows. The results were clear: the non-AI-assisted programmers solved more tasks correctly and fewer tasks incorrectly than the group that used LLMs for help.
\ Let that sink in: in a complex debugging task, having a state-of-the-art AI assistant was not just unhelpful—it was actively detrimental, leading to worse outcomes than having no AI at all. Participants using AI frequently got stuck in these fruitless loops, wasting time on conceptually baseless fixes. Researchers also identified the "noisy solution" problem, where a correct fix is buried within a flurry of irrelevant suggestions, a perfect recipe for human frustration. This flawed "assistance" highlights how AI's impressive veneer can hide a deeply unreliable core, especially when the stakes are high.
Their Impressive Benchmarks Are Built on a Foundation of Flaws
When AI companies release new models, they point to impressive benchmark scores to prove their superiority. A closer look, however, can reveal a much less flattering picture.
\ The SWE-bench (Software Engineering Benchmark), used to measure an LLM's ability to fix real-world software issues from GitHub, is a prime case study. An independent study from York University found critical flaws that wildly inflated the models' perceived capabilities:
\
- Solution Leakage ("Cheating"): In 32.67% of successful patches, the correct solution was already provided in the issue report itself.
- Weak Tests: In 31.08% of cases where the model "passed," the verification tests were too weak to actually confirm the fix was correct.
\ When these flawed instances were filtered out, the real-world performance of a top model (SWE-Agent + GPT-4) plummeted. Its resolution rate dropped from an advertised 12.47% to just 3.97%. Furthermore, over 94% of the issues in the benchmark were created before the LLMs' knowledge cutoff dates, raising serious questions about data leakage.
\ This reveals a troubling reality: benchmarks are often marketing tools that present a best-case, lab-grown scenario, which crumbles under real-world scrutiny. The gap between advertised power and verified performance is not a crack; it's a canyon.
They Master Rules But Fundamentally Lack Understanding
Even if all the technical failures above were fixed, a deeper, more philosophical barrier remains. LLMs lack the core components of human intelligence. While philosophers discuss consciousness and intentionality, many arguments suggest that rationality, aka our ability to grasp universal concepts and reason logically, is the key aspect unique to humans and absent in AI.
\ This idea is reinforced by physicist Roger Penrose, who uses Gödel’s incompleteness theorem to argue that human mathematical understanding transcends any fixed set of algorithmic rules. Think of any algorithm as a finite rulebook. Gödel's theorem shows that a human mathematician can always look at the rulebook from the outside and understand truths that the rulebook itself cannot prove.
\ Our minds are not just following the rules in the book; we can read the whole book and grasp its limitations. This capacity for insight, this "non-computable" understanding, is what separates human cognition from even the most advanced AI.
\ LLMs are masters of manipulating symbols based on algorithms and statistical patterns. They do not, however, possess the awareness required for genuine understanding. As one powerful argument concludes:
The Magician's Trick
While LLMs are undeniably powerful tools that can simulate intelligent behavior with uncanny accuracy, the mounting evidence shows they are more like sophisticated simulators than genuine thinkers. Their performance is a grand illusion, a dazzling spectacle of competence that falls apart under pressure, contradicts its own logic, and relies on flawed metrics. It is akin to a magician's trick (seemingly impossible), but ultimately an illusion built on clever techniques, not actual magic. As we continue to integrate these systems into our world, we must remain critical and ask the essential question:
\ If these AI machines break down on harder problems, even when you give them the algorithms and rules, are they actually thinking or just faking it really well?
Podcast:
\
- Apple: HERE
- Spotify: HERE
\


You May Also Like

Pi Network Wallet Upgrade Signals Multi Asset Support and Web3 Ecosystem Expansion

China to import record 800,000 tonnes of US ethane amid Iran conflict




