

MaGGIe Architecture: Efficient Mask-Guided Instance Matting
Table of Links
Abstract and 1. Introduction
-
Related Works
-
MaGGIe
3.1. Efficient Masked Guided Instance Matting
3.2. Feature-Matte Temporal Consistency
-
Instance Matting Datasets
4.1. Image Instance Matting and 4.2. Video Instance Matting
-
Experiments
5.1. Pre-training on image data
5.2. Training on video data
-
Discussion and References
\ Supplementary Material
-
Architecture details
-
Image matting
8.1. Dataset generation and preparation
8.2. Training details
8.3. Quantitative details
8.4. More qualitative results on natural images
-
Video matting
9.1. Dataset generation
9.2. Training details
9.3. Quantitative details
9.4. More qualitative results
3. MaGGIe
We introduce our efficient instance matting framework guided by instance binary masks, structured into two parts. The first Sec. 3.1 details our novel architecture to maintain accuracy and efficiency. The second Sec. 3.2 describes our approach for ensuring temporal consistency across frames in video processing.
3.1. Efficient Masked Guided Instance Matting
\ 
\ In cross-attention (CA), Q and (K, V) originate from different sources, whereas in self-attention (SA), they share similar information.
\ 
\ 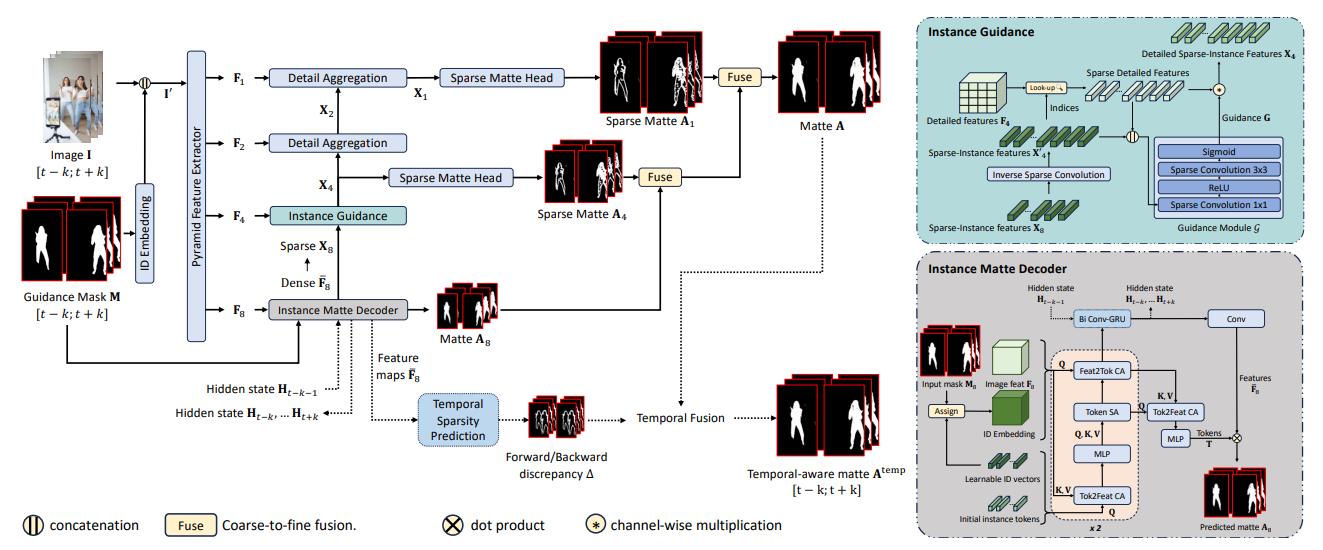
\ where {; } denotes concatenation along the feature dimension, and G is a series of sparse convolutions with sigmoid activation.
\ 
\
:::info Authors:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
\
You May Also Like

Aave DAO to Shut Down 50% of L2s While Doubling Down on GHO

DeAgentAI releases new white paper, detailing $AIA token economics and staking model


