

Résoudre le plus grand goulot d'étranglement de la segmentation 3D
:::info Auteurs :
(1) George Tang, Massachusetts Institute of Technology ;
(2) Krishna Murthy Jatavallabhula, Massachusetts Institute of Technology ;
(3) Antonio Torralba, Massachusetts Institute of Technology.
:::
Table des liens
Résumé et I. Introduction
II. Contexte
III. Méthode
IV. Expériences
V. Conclusion et Références
\ 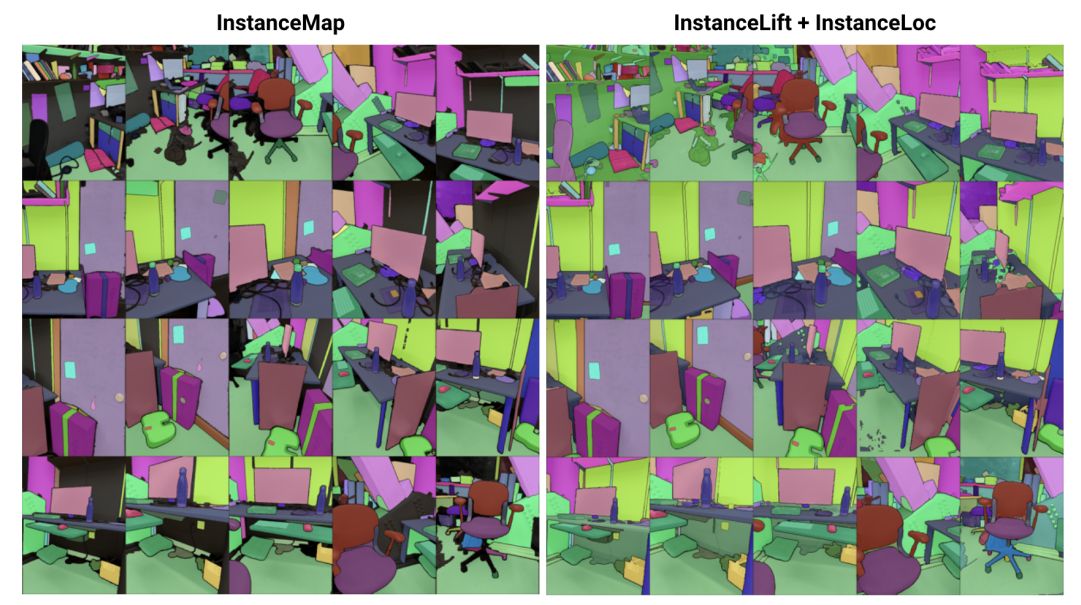
\ Résumé— Nous abordons le problème de l'apprentissage d'une représentation implicite de scène pour la segmentation d'instances 3D à partir d'une séquence d'images RGB posées. Pour ce faire, nous introduisons 3DIML, un nouveau cadre qui apprend efficacement un champ d'étiquettes pouvant être rendu à partir de nouveaux points de vue pour produire des masques de segmentation d'instances cohérents. 3DIML améliore considérablement les temps d'exécution d'entraînement et d'inférence des méthodes existantes basées sur la représentation implicite de scènes. Contrairement aux méthodes antérieures qui optimisent un champ neuronal de manière auto-supervisée, nécessitant des procédures d'entraînement compliquées et une conception de fonction de perte complexe, 3DIML s'appuie sur un processus en deux phases. La première phase, InstanceMap, prend en entrée des masques de segmentation 2D de la séquence d'images générés par un modèle de segmentation d'instances frontend, et associe les masques correspondants à travers les images à des étiquettes 3D. Ces masques pseudo-étiquettes presque cohérents entre les vues sont ensuite utilisés dans la deuxième phase, InstanceLift, pour superviser l'entraînement d'un champ d'étiquettes neuronal, qui interpole les régions manquées par InstanceMap et résout les ambiguïtés. De plus, nous introduisons InstanceLoc, qui permet une localisation en temps quasi réel des masques d'instances étant donné un champ d'étiquettes entraîné et un modèle de segmentation d'image prêt à l'emploi en fusionnant les sorties des deux. Nous évaluons 3DIML sur des séquences des ensembles de données Replica et ScanNet et démontrons l'efficacité de 3DIML sous des hypothèses modérées pour les séquences d'images. Nous obtenons une accélération pratique importante par rapport aux méthodes existantes de représentation implicite de scènes avec une qualité comparable, démontrant son potentiel pour faciliter une compréhension de scène 3D plus rapide et plus efficace.
I. INTRODUCTION
Les agents intelligents nécessitent une compréhension de la scène au niveau de l'objet pour effectuer efficacement des actions contextuelles telles que la navigation et la manipulation. Bien que la segmentation d'objets à partir d'images ait connu des progrès remarquables avec des modèles évolutifs entraînés sur des ensembles de données à l'échelle d'Internet [1], [2], l'extension de ces capacités au cadre 3D reste difficile.
\ Dans ce travail, nous abordons le problème de l'apprentissage d'une représentation de scène 3D à partir d'images 2D posées qui factorise la scène sous-jacente en son ensemble d'objets constitutifs. Les approches existantes pour résoudre ce problème se sont concentrées sur l'entraînement de modèles de segmentation 3D agnostiques aux classes [3], [4], nécessitant de grandes quantités de données 3D annotées et opérant directement sur des représentations de scènes 3D explicites (par exemple, des nuages de points). Une classe alternative d'approches [5], [6] a plutôt proposé de transposer directement les masques de segmentation de modèles de segmentation d'instances prêts à l'emploi en représentations 3D implicites, telles que les champs de radiance neuronaux (NeRF) [7], leur permettant de rendre des masques d'instances 3D cohérents à partir de nouveaux points de vue.
\ Cependant, les approches basées sur les champs neuronaux sont restées notoirement difficiles à optimiser, [5] et [6] prenant plusieurs heures pour optimiser des images de résolution faible à moyenne (par exemple, 300 × 640). En particulier, Panoptic Lifting [5] évolue de manière cubique avec le nombre d'objets dans la scène, l'empêchant d'être appliqué à des scènes contenant des centaines d'objets, tandis que Contrastively Lifting [6] nécessite une procédure d'entraînement compliquée en plusieurs étapes, entravant la praticité pour une utilisation dans des applications robotiques.
\ À cette fin, nous proposons 3DIML, une technique efficace pour apprendre la segmentation d'instances 3D cohérente à partir d'images RGB posées. 3DIML comprend deux phases : InstanceMap et InstanceLift. Étant donné des masques d'instances 2D incohérents entre les vues extraits de la séquence RGB à l'aide d'un modèle de segmentation d'instances frontend [2], InstanceMap produit une séquence de masques d'instances cohérents entre les vues. Pour ce faire, nous associons d'abord les masques entre les images en utilisant des correspondances de points-clés entre des paires d'images similaires. Nous utilisons ensuite ces associations potentiellement bruitées pour superviser un champ d'étiquettes neuronal, InstanceLift, qui exploite la structure 3D pour interpoler les étiquettes manquantes et résoudre les ambiguïtés. Contrairement aux travaux antérieurs, qui nécessitent un entraînement en plusieurs étapes et une ingénierie supplémentaire de la fonction de perte, nous utilisons une seule perte de rendu pour la supervision des étiquettes d'instances, permettant au processus d'entraînement de converger significativement plus rapidement. Le temps d'exécution total de 3DIML, y compris InstanceMap, prend 10-20 minutes, contre 3-6 heures pour les méthodes antérieures.
\ De plus, nous concevons InstaLoc, un pipeline de localisation rapide qui prend une nouvelle vue et localise toutes les instances segmentées dans cette image (en utilisant un modèle de segmentation d'instances rapide [8]) en interrogeant de manière éparse le champ d'étiquettes et en fusionnant les prédictions d'étiquettes avec les régions d'image extraites. Enfin, 3DIML est extrêmement modulaire, et nous pouvons facilement échanger des composants de notre méthode pour des composants plus performants à mesure qu'ils deviennent disponibles.
\ Pour résumer, nos contributions sont :
\ • Une approche efficace d'apprentissage de champ neuronal qui factorise une scène 3D en ses objets constitutifs
\ • Un algorithme rapide de localisation d'instances qui fusionne des requêtes éparses au champ d'étiquettes entraîné avec des modèles performants de segmentation d'instances d'images pour générer des masques de segmentation d'instances 3D cohérents
\ • Une amélioration pratique globale du temps d'exécution de 14-24× par rapport aux méthodes antérieures, évaluée sur un seul GPU (NVIDIA RTX 3090)
II. CONTEXTE
Segmentation 2D : La prévalence de l'architecture des transformers de vision et l'échelle croissante des ensembles de données d'images ont abouti à une série de modèles de segmentation d'images à la pointe de la technologie. Panoptic et Contrastive Lifting transposent tous deux les masques de segmentation panoptique produits par Mask2Former [1] en 3D en apprenant un champ neuronal. Pour la segmentation en ensemble ouvert, segment anything (SAM) [2] atteint des performances sans précédent en s'entraînant sur un milliard de masques sur 11 millions d'images. HQ-SAM [9] améliore SAM pour les masques fins. FastSAM [8] distille SAM dans une architecture CNN et atteint des performances similaires tout en étant des ordres de grandeur plus rapide. Dans ce travail, nous utilisons GroundedSAM [10], [11], qui affine SAM pour produire une segmentation au niveau de l'objet, par opposition à la segmentation au niveau des parties.
\ Champs neuronaux pour la segmentation d'instances 3D : Les NeRFs sont des représentations de scènes implicites qui peuvent encoder avec précision une géométrie complexe, des sémantiques et d'autres modalités, ainsi que résoudre une supervision incohérente du point de vue [12]. Panoptic lifting [5] construit des branches sémantiques et d'instances sur une variante efficace de NeRF, TensoRF [13], en utilisant une fonction de perte d'appariement hongroise pour attribuer des masques d'instances appris à des identifiants d'objets de substitution étant donné des masques de référence incohérents entre les vues. Cela évolue mal avec l'augmentation du nombre d'objets (en raison de la complexité cubique de l'appariement hongrois). Contrastive lifting [6] aborde ce problème en employant plutôt l'apprentissage contrastif sur les caractéristiques de la scène, avec des relations positives et négatives déterminées selon qu'elles se projettent ou non sur le même masque. De plus, contrastive lifting nécessite une perte basée sur le clustering lent-rapide pour un entraînement stable, conduisant à des performances plus rapides que panoptic lifting mais nécessitant plusieurs étapes d'entraînement, menant à une convergence lente. Parallèlement à nous, Instance-NeRF [14] apprend directement un champ d'étiquettes, mais ils basent leur association de masques sur l'utilisation de NeRF-RPN [15] pour détecter des objets dans un NeRF. Notre approche, au contraire, permet de passer à des résolutions d'image très élevées tout en ne nécessitant qu'un petit nombre (40-60) de requêtes de champ neuronal pour rendre des masques de segmentation.
\ Structure from Motion : Pendant l'association de masques dans InstanceMap, nous nous inspirons des pipelines de reconstruction 3D évolutifs tels que hLoc [16], y compris l'utilisation de descripteurs visuels pour faire correspondre d'abord les points de vue des images, puis appliquer la correspondance de points-clés comme préliminaire à l'association de masques. Nous utilisons LoFTR [17] pour l'extraction et la correspondance de points-clés.
\
:::info Cet article est disponible sur arxiv sous licence CC by 4.0 Deed (Attribution 4.0 International).
:::
\


Vous aimerez peut-être aussi

L'administration Trump suscite une « véritable inquiétude » avec une demande soudaine aux agences : rapport

Actualités du marché aujourd'hui : Découvrez le top 7 des Memes Coins à faible capitalisation en hausse dans le chaos crypto sauvage – La prévente APEMARS se démarque




