

How to Improve AI Models While Training Only 0.1% of Parameters
:::info Authors:
(1) Yaqing Wang, Purdue University (wang5075@purdue.edu);
(2) Sahaj Agarwal, Microsoft (sahagar@microsoft.com);
(3) Subhabrata Mukherjee, Microsoft Research (submukhe@microsoft.com);
(4) Xiaodong Liu, Microsoft Research (xiaodl@microsoft.com);
(5) Jing Gao, Purdue University (jinggao@purdue.edu);
(6) Ahmed Hassan Awadallah, Microsoft Research (hassanam@microsoft.com);
(7) Jianfeng Gao, Microsoft Research (jfgao@microsoft.com).
:::
Table of Links
Abstract and 1. Introduction
-
Background
2.1 Mixture-of-Experts
2.2 Adapters
-
Mixture-of-Adaptations
3.1 Routing Policy
3.2 Consistency regularization
3.3 Adaptation module merging and 3.4 Adaptation module sharing
3.5 Connection to Bayesian Neural Networks and Model Ensembling
-
Experiments
4.1 Experimental Setup
4.2 Key Results
4.3 Ablation Study
-
Related Work
-
Conclusions
-
Limitations
-
Acknowledgment and References
Appendix
A. Few-shot NLU Datasets B. Ablation Study C. Detailed Results on NLU Tasks D. Hyper-parameter
Abstract
Standard fine-tuning of large pre-trained language models (PLMs) for downstream tasks requires updating hundreds of millions to billions of parameters, and storing a large copy of the PLM weights for every task resulting in increased cost for storing, sharing and serving the models. To address this, parameter-efficient fine-tuning (PEFT) techniques were introduced where small trainable components are injected in the PLM and updated during fine-tuning. We propose AdaMix as a general PEFT method that tunes a mixture of adaptation modules – given the underlying PEFT method of choice – introduced in each Transformer layer while keeping most of the PLM weights frozen. For instance, AdaMix can leverage a mixture of adapters like Houlsby (Houlsby et al., 2019) or a mixture of low rank decomposition matrices like LoRA (Hu et al., 2021) to improve downstream task performance over the corresponding PEFT methods for fully supervised and few-shot NLU and NLG tasks. Further, we design AdaMix such that it matches the same computational cost and the number of tunable parameters as the underlying PEFT method. By only tuning 0.1 − 0.2% of PLM parameters, we show that AdaMix outperforms SOTA parameter-efficient fine-tuning and full model fine-tuning for both NLU and NLG tasks. Code and models are made available at https://aka.ms/AdaMix.
1 Introduction
Standard fine-tuning of large pre-trained language models (PLMs) (Devlin et al., 2019; Liu et al., 2019; Brown et al., 2020; Raffel et al., 2019) to downstream tasks requires updating all model parameters. Given the ever-increasing size of PLMs (e.g., 175 billion parameters for GPT-3 (Brown et al., 2020) and 530 billion parameters for MTNLG (Smith et al., 2022)), even the fine-tuning step becomes expensive as it requires storing a full copy
\ 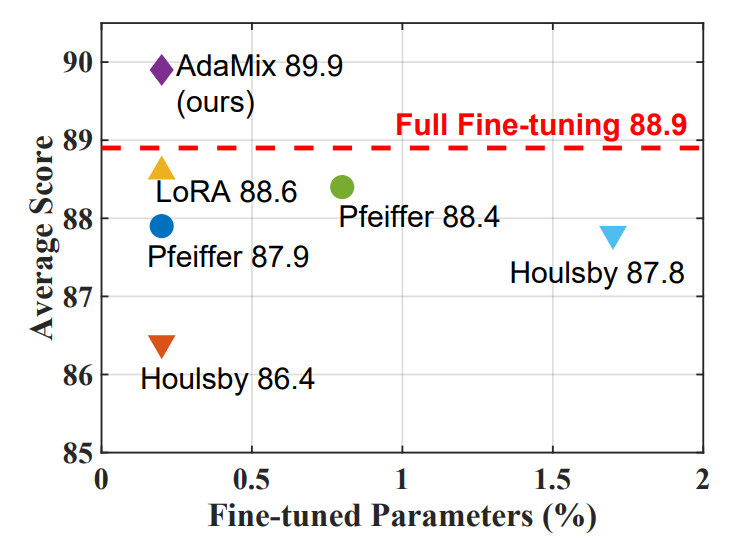
\ of model weights for every task. To address these challenges, recent works have developed parameterefficient fine-tuning (PEFT) techniques. These approaches typically underperform standard full model fine-tuning, but significantly reduce the number of trainable parameters. There are many varieties of PEFT methods, including prefix-tuning (Li and Liang, 2021) and prompt-tuning (Lester et al., 2021) to condition frozen language models via natural language task descriptions, low dimensional projections using adapters (Houlsby et al., 2019; Pfeiffer et al., 2020, 2021) and more recently using low-rank approximation (Hu et al., 2021). Figure 1 shows the performance of some popular PEFT methods with varying number of tunable parameters. We observe a significant performance gap with respect to full model tuning where all PLM parameters are updated.
\ In this paper, we present AdaMix, a mixture of adaptation modules approach, and show that it outperforms SOTA PEFT methods and also full model fine-tuning while tuning only 0.1 − 0.2% of PLM parameters.
\ In contrast to traditional PEFT methods that use a single adaptation module in every Transformer layer, AdaMix uses several adaptation modules that learn multiple views of the given task. In order to design this mixture of adaptations, we take inspiration from sparsely-activated mixture-of-experts (MoE) models. In traditional dense models (e.g., BERT (Devlin et al., 2019), GPT-3 (Brown et al., 2020)), all model weights are activated for every input example. MoE models induce sparsity by activating only a subset of the model weights for each incoming input.
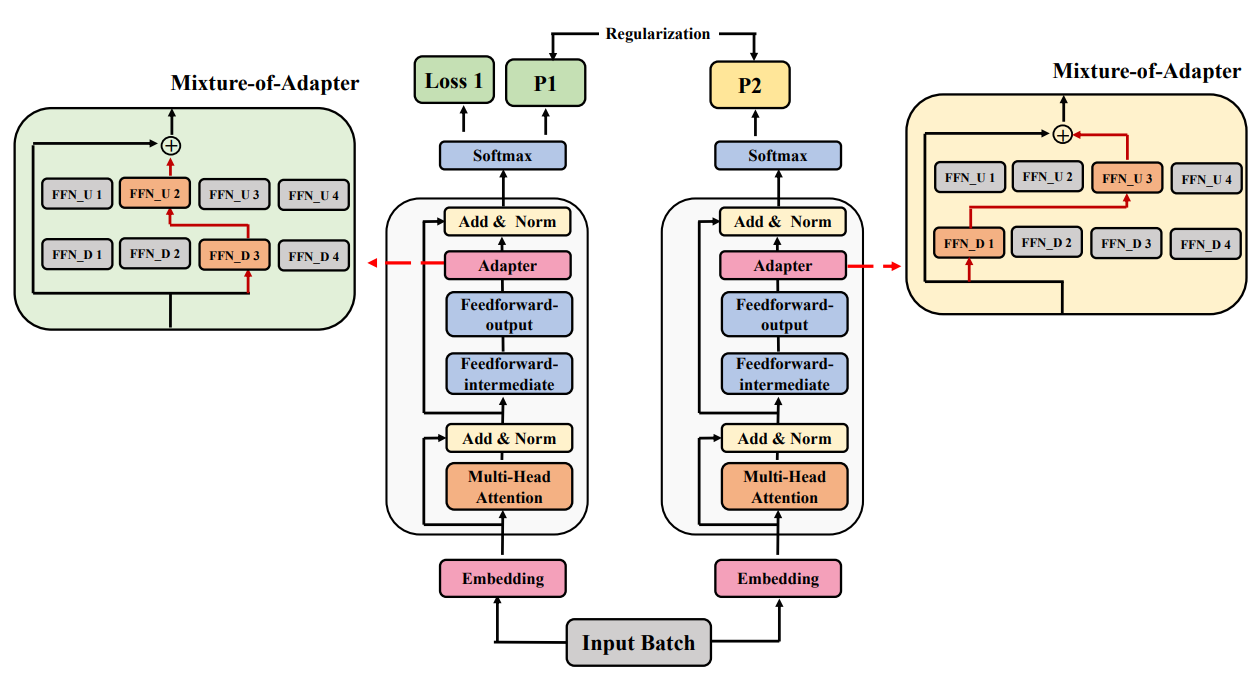
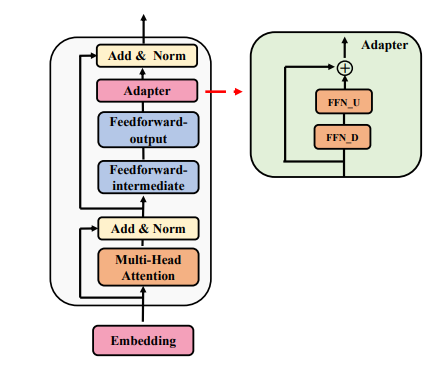
\ Consider adapters (Houlsby et al., 2019), one of the most popular PEFT techniques, to illustrate our method. A feedforward layer (FFN) is introduced to down-project the hidden representation to a low dimension d (also called the bottleneck dimension) followed by another up-project FFN to match the dimensionality of the next layer. Instead of using a single adapter, we introduce multiple project-up and project-down FFNs in each Transformer layer. We route input examples to one of the project-up and one of the project-down FFN’s resulting in the same amount of computational cost (FLOPs) as that of using a single adapter. For methods like LoRA (Hu et al., 2021), that decomposes the gradient of pre-trained weights into low-rank matrices (A and B), we introduce multiple lowrank decompositions and route the input examples to them similar to adapters.
\ We discuss different routing mechanism and show that stochastic routing yields good performance while eliminating the need for introducing any additional parameters for module selection. To alleviate training instability that may arise from the randomness in selecting different adaptation modules in different training steps, we leverage consistency regularization and the sharing of adaptation modules during stochastic routing.
\ The introduction of multiple adaptation modules results in an increased number of adaptation parameters. This does not increase computational cost but increases storage cost. To address this, we develop a merging mechanism to combine weights from different adaptation modules to a single module in each Transformer layer. This allows us to keep the number of adaptation parameters the same as that of a single adaptation module. Our merging mechanism is inspired by model weight averaging model soups (Wortsman et al., 2022) and multi BERTs (Sellam et al., 2022). Weight averaging of models with different random initialization has been shown to improve model performance in recent works (Matena and Raffel, 2021; Neyshabur et al., 2020; Frankle et al., 2020) that show the optimized models to lie in the same basin of error landscape. While the above works are geared towards fine-tuning independent models, we extend this idea to parameter-efficient fine-tuning with randomly initialized adaptation modules and a frozen language model.
\ Overall, our work makes the following contributions:
\ (a) We develop a new method AdaMix as a mixture of adaptations for parameter-efficient fine-tuning (PEFT) of large language models. Given any PEFT method of choice like adapters and low-rank decompositions, AdaMix improves downstream task performance over the underlying PEFT method.
\ (b) AdaMix is trained with stochastic routing and adaptation module merging to retain the same computational cost (e.g., FLOPs, #tunable adaptation parameters) and benefits of the underlying PEFT method. To better understand how AdaMix works, we demonstrate its strong connections to Bayesian Neural Networks and model ensembling.
\ (c) By tuning only 0.1 − 0.2% of a pre-trained language model’s parameters, AdaMix is the first PEFT method to outperform full model fine-tuning methods for all NLU tasks on GLUE, and outperforms other competing methods for NLG and few-shot NLU tasks.
\ Practical benefits of PEFT methods. The most significant benefit of PEFT methods comes from the reduction in memory and storage usage. For a Transformer, the VRAM consumption can be significantly reduced as we do not need to keep track of optimizer states for the frozen parameters. PEFT methods also allow multiple tasks to share the same copy of the full (frozen) PLM. Hence, the storage cost for introducing a new task can be reduced by up to 444x (from 355MB to 0.8MB with RoBERTa-large encoder in our setting).
\ We present background on Mixture-of-Experts (MoE) and adapters in Section 2 of Appendix.
\
2 Background
2.1 Mixture-of-Experts
\ 
\ \ \ 
\ \ \ 
\ \ \ 
\
2.2 Adapters
The predominant methodology for task adaptation is to tune all of the trainable parameters of the PLMs for every task. This raises significant resource challenges both during training and deployment. A recent study (Aghajanyan et al., 2021) shows that PLMs have a low instrinsic dimension that can match the performance of the full parameter space.
\ To adapt PLMs for downstream tasks with a small number of parameters, adapters (Houlsby et al., 2019) have recently been introduced as an alternative approach for lightweight tuning.
\ \ 
\
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
You May Also Like

The Channel Factories We’ve Been Waiting For


American Bitcoin’s $5B Nasdaq Debut Puts Trump-Backed Miner in Crypto Spotlight
