New Dataset PerSense-D Enables Model-Agnostic Dense Object Segmentation

Table of Links
Abstract and 1. Introduction
-
Related Work
-
Method
3.1 Class-label Extraction and Exemplar Selection for FSOC
3.2 Instance Detection Module (IDM) and 3.3 Point Prompt Selection Module (PPSM)
3.4 Feedback Mechanism
-
New Dataset (PerSense-D)
-
Experiments
-
Conclusion and References
A. Appendix
4 New Dataset (PerSense-D)
PerSense utilizes DMs, generated by FSOC, for point prompt extraction using IDM and PPSM. These DMs are specific to dense and crowded images where we have several instances of an object in an image. Existing segmentation datasets do not fulfill our requirement of exclusively gathering dense images, which can be used for personalized segmentation in dense images. While certain images within the COCO [11], LVIS [12], and FSS-1000 [13] datasets may feature multiple instances of the same object category, the majority of images fail to meet the criteria for our intended application. This is due to the limited number of object instances present within each image. For example, on average each image in LVIS [12] is annotated with 11.2 instances from 3.4 object categories. This results in an average of 3.3 instances per single category, which falls short of meeting our requirement for a dataset exclusively focusing on dense images.
\ We therefore introduce PerSense-D, a diverse dataset exclusive to segmentation in dense images. PerSense-D comprises 717 images distributed across 28 object categories, with an average count of 39 objects per image. The dataset goal is to support the development of practical tools for various applications, including object counting, quality control, and cargo monitoring in industrial automation. Its utility extends across diverse domains such as medical, agriculture, environmental monitoring, autonomous systems, and retail, where precise segmentation improves decision-making, safety, and operational effectiveness. Given our focus on one-shot personalized dense image segmentation, we explicitly supply 28 support images labeled as "00", each containing a single object instance intended for personalized segmentation in the corresponding object category. This can facilitate fair evaluation among various one-shot approaches as no random seeding is required.
\ Image Collection and Retrieval: Out of 717 images, we have 689 dense query images and 28 support images. To acquire the set of 689 dense images, we initiated the process with a collection of candidate images obtained through keyword searches. To mitigate bias, we retrieved the candidate images by querying object keywords across three distinct Internet search engines: Google, Bing, and Yahoo. To diversify the search query keywords, we prefixed adjectives such as ’multiple’, ’lots of’, and ’many’ before the category names. In every search, we collected the first 100 images that fall under CC BY-NC 4.0 licensing terms. With 28 categories, we gathered a total of 2800 images, which were subsequently filtered in the next step.
\ Manual Inspection and Filtering: The candidate images were manually inspected following a three-point criterion. (1) The image quality and resolution should be sufficiently high to enable easy differentiation between objects. (2) Following the criterion in object counting dataset FSC-147 [23], we set the minimum object count to 7 per image for our PerSense-D benchmark. (3) The image shall contain a challenging dense environment with sufficient occlusions among object instances along with background clutter. Based on this criterion, we filtered 689 images out of 2800 candidates.
\ 
\ Semi-automatic Image Annotation Pipeline: We crowdsourced the annotation task under appropriate institutional approval. We devised a semi-automatic annotation pipeline. Following the model-in-the-loop strategy outlined in [1], we utilized our PerSense to provide an initial segmentation mask. This initial mask was then manually refined and corrected by annotators using pixel-precise tools such as the OpenCV image annotation tool and Photoshop’s “quick selection" and "lasso" tool, which allows users to loosely select an object automatically. As the images were dense, the average time to manually refine single image annotation was around 15 minutes.
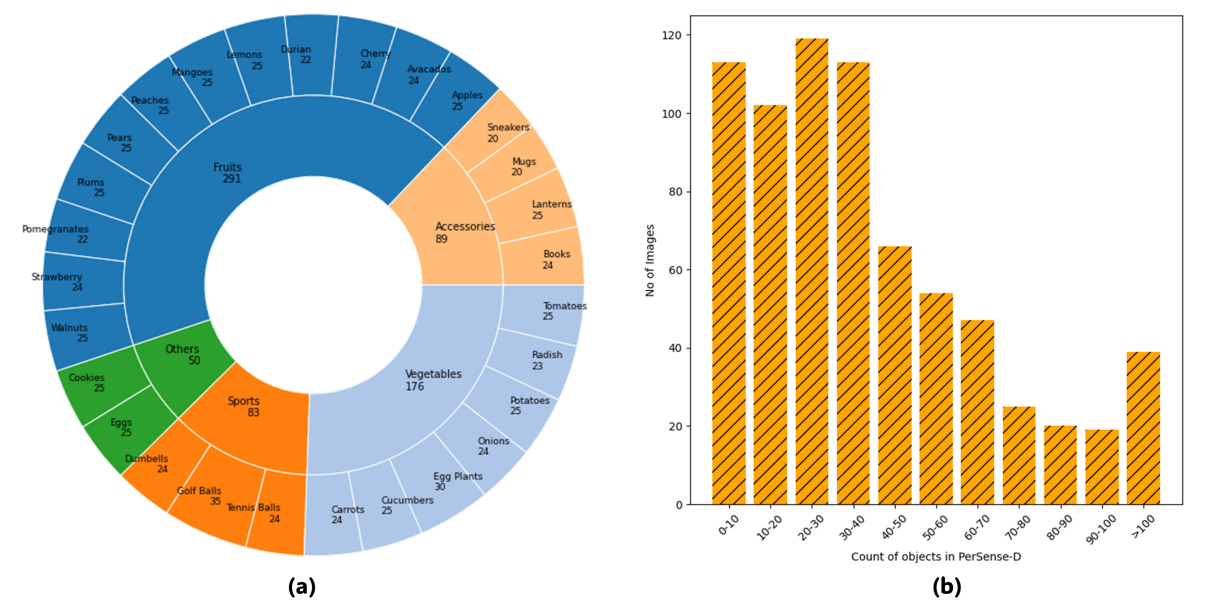
\ Dataset Statistics: The dataset contains a total of 717 images (689 query and 28 support images). Average count is 39 objects per image, with a total of 28,395 objects across the entire dataset. The minimum and maximum number of objects in a single image are 7 and 218, respectively. The average resolution (height x width) of images is 839 x 967 pixels. Figure 5 presents detail of object categories in PerSense-D and a histogram depicting the number of images across various ranges of object count.
5 Experiments
Implementation Details and Evaluation Metrics: Our PerSense is model-agnostic and leverages a VLM, grounding detector, and FSOC for personalized instance segmentation in dense images. For VLM, we follow VIP-LLaVA [24], which utilizes CLIP-336px [25] and Vicuna v1.5 [26] as visual and language encoders, respectively. We use GroundingDINO [4] as the grounding detector and utilize DSALVANet [27] pretrained on FSC-147 dataset [23] as FSOC. For GroundingDINO, we lowered the detection_threshold to 15%, to minimize rejection of true positives (see ablation study below). Finally, we utilize SAM [1] encoder and decoder for personalized segmentation following the approach in [2]. We evaluate segmentation performance on the PerSense-D dataset using the standard evaluation metric of mIoU (mean Intersection over Union). No training is involved in any of our experiments.
\ Results: Grounded-SAM [3], a combination of a powerful grounding detector and SAM constitutes a SOTA approach specifically targeting automated dense image segmentation tasks. Therefore, we
\ 
\ 
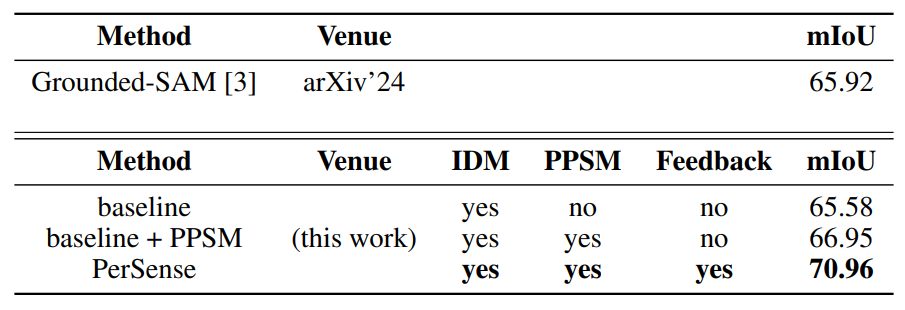
\ compare our PerSense with Grounded-SAM and utilize PerSense-D as evaluation benchmark. To be fair in comparison, we ensured that all classes in PerSense-D overlaps with at least one of the datasets on which GroundingDINO is pre-trained. Importantly, all the classes in PerSense-D are common in Objects365 dataset [28]. The class-label extracted by VLM in PerSense (sec 3.1), using one-shot data, is also fed to Grounded-SAM for personalized segmentation. We report the results in Table 1, where PerSense achieves 70.96% mIoU, surpassing SOTA approach by +5.04%. Furthermore, it can be observed that even with our baseline network, we were able to achieve performance comparable to Grounded-SAM. Also, if we omit the feedback mechanism, PerSense can still surpass GroundedSAM by +1.03%. This increase in performance is credited to the combination of our IDM and PPSM, which ensures precise localization of each personalized instance. Figure 7 showcases our qualitative results. For qualitative analysis of PerSense at each step, please see Appendix A.3.
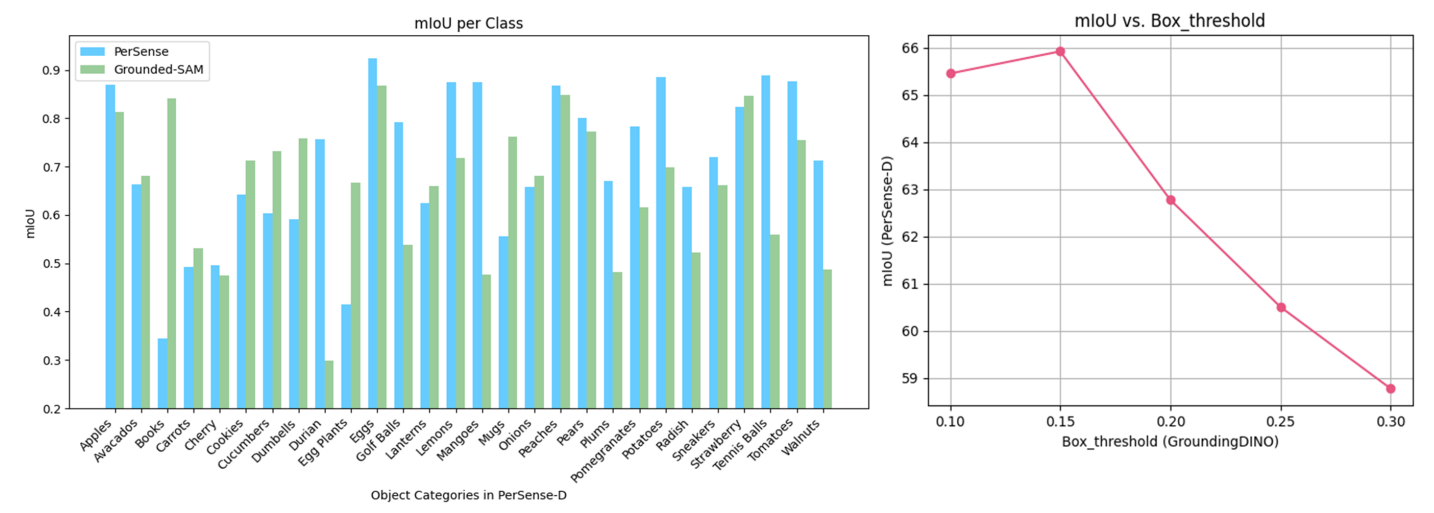
Discussion: We provide a class-wise comparison of mIoU on PerSense-D considering PerSense and Grounded-SAM (Figure 6, Left). We observe that object categories such as "Durian," "Mangoes", "Walnuts", etc., which have minimal demarcation between object instances, are accurately segmented by PerSense. Grounded-SAM, however, segments undesired regions between object instances due to limitations associated with the bounding box-based detections. In contrast, for object categories with zero separation between multiple instances or tightly merged flat boundaries, Groounded-SAM performs better than our PerSense. For instance, majority of images in the "Books" category feature piles and stacks of books, which offers a favorable scenario for bounding box-based detections but it is relatively challenging to generate precise point prompts for each book in a tightly packed pile with no obvious separation between object boundaries. Moreover, for object categories such as "Eggplants," "Cookies," "Cucumbers," and "Dumbbells," which exhibit significant intra-class variation, the segmentation performance of our PerSense is understandably reduced compared to Grounded-SAM, as it is restricted to personalized instance segmentation in the one-shot context. The average time taken by PerSense to segment an image on a single NVIDIA GeForce RTX 4090 GPU is approx 2.7 sec per image, while Grounded-SAM takes about 1.8 sec under similar conditions. This results in a temporal overhead of approx 0.9 sec for our PerSense, establishing a trade-off between inference time and segmentation performance relative to Grounded-SAM. These insights can assist in selection of preferable approach based on the target application.
\ Ablation Study: We conducted an ablation study to explore the impact of varying the detection threshold in GroundingDINO to maximize segmentation performance for Grounded-SAM(Figure 6, Right). The bounding box threshold of GroundingDINO was varied from 0.10 to 0.30 with a stepsize of 0.5. Ultimately for comparison with PerSense, we selected 0.15 as the box threshold as it resulted in the highest mIoU for Grounded-SAM considering PerSense-D as the benchmark. We used the same threshold for GroundingDINO in our PerSense to ensure fairness in comparison.
6 Conclusion
We presented PerSense, a training-free and model-agnostic one-shot framework for personalized instance segmentation in dense images. We proposed IDM and PPSM, which transforms density
\ \
:::info Authors:
(1) Muhammad Ibraheem Siddiqui, Department of Computer Vision, Mohamed bin Zayed University of AI, Abu Dhabi (muhammad.siddiqui@mbzuai.ac.ae);
(2) Muhammad Umer Sheikh, Department of Computer Vision, Mohamed bin Zayed University of AI, Abu Dhabi;
(3) Hassan Abid, Department of Computer Vision, Mohamed bin Zayed University of AI, Abu Dhabi;
(4) Muhammad Haris Khan, Department of Computer Vision, Mohamed bin Zayed University of AI, Abu Dhabi.
:::
:::info This paper is available on arxiv under CC BY-NC-SA 4.0 Deed (Attribution-Noncommercial-Sharelike 4.0 International) license.
:::
\


You May Also Like

PENGU climbs 17%, Market awaits break above $0.0102

XRP Coils at Key Support: Breakout to $1.50 Ahead?